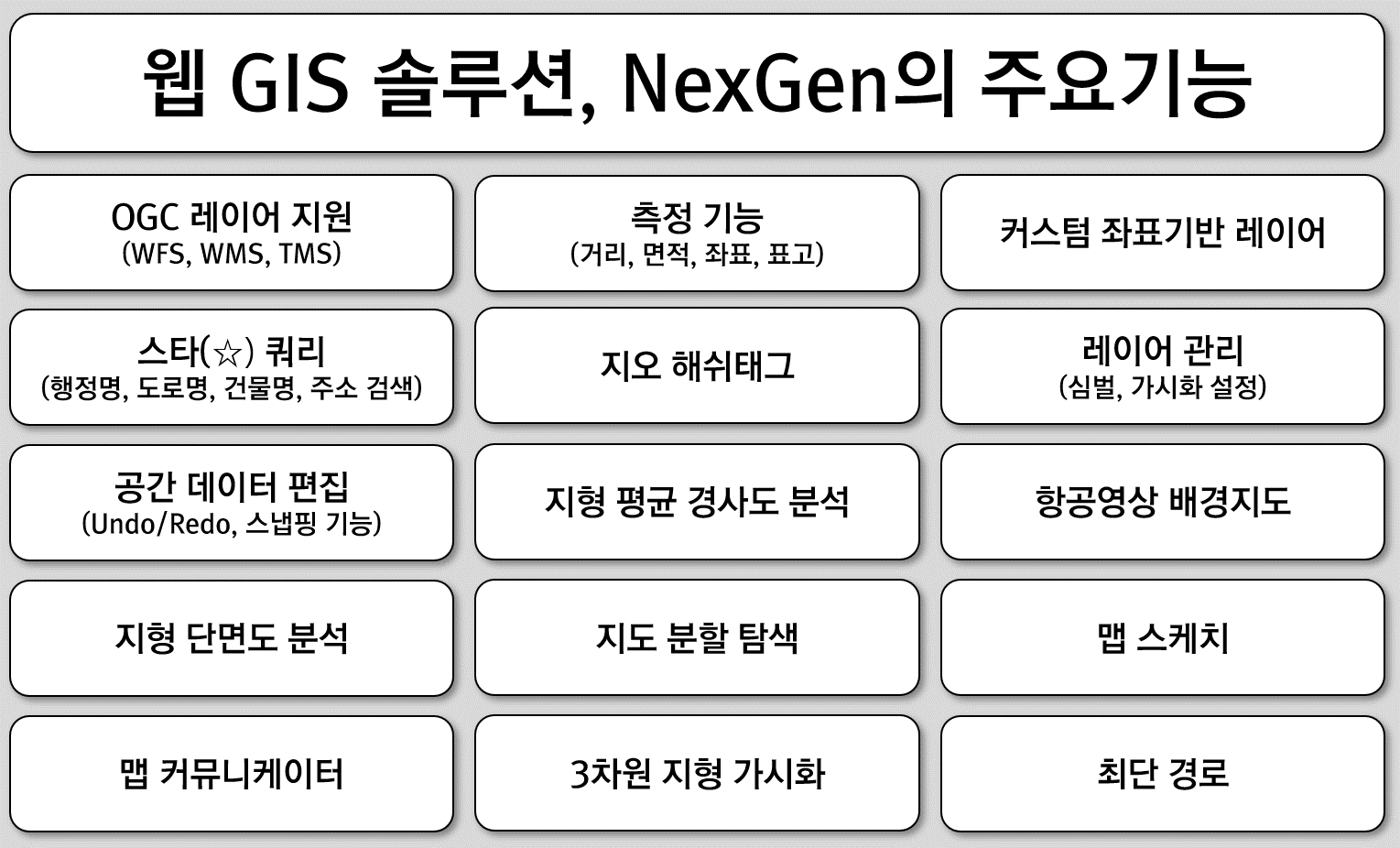
FingerEyes-Xr은 웹에서 지도를 표시하고, 표시된 지도와 연관된 기능을 제공할 수 있는 맵 컴포넌트입니다. GitHub에 소스가 공개되어 있으며, 다양한 GIS 시스템 개발을 위한 핵심 맵 컴포넌트로 활용되었고 웹 GIS 솔루션, NexGen에서도 지도 표출 및 다양한 지도 관련 기능을 위한 컴포넌트입니다.
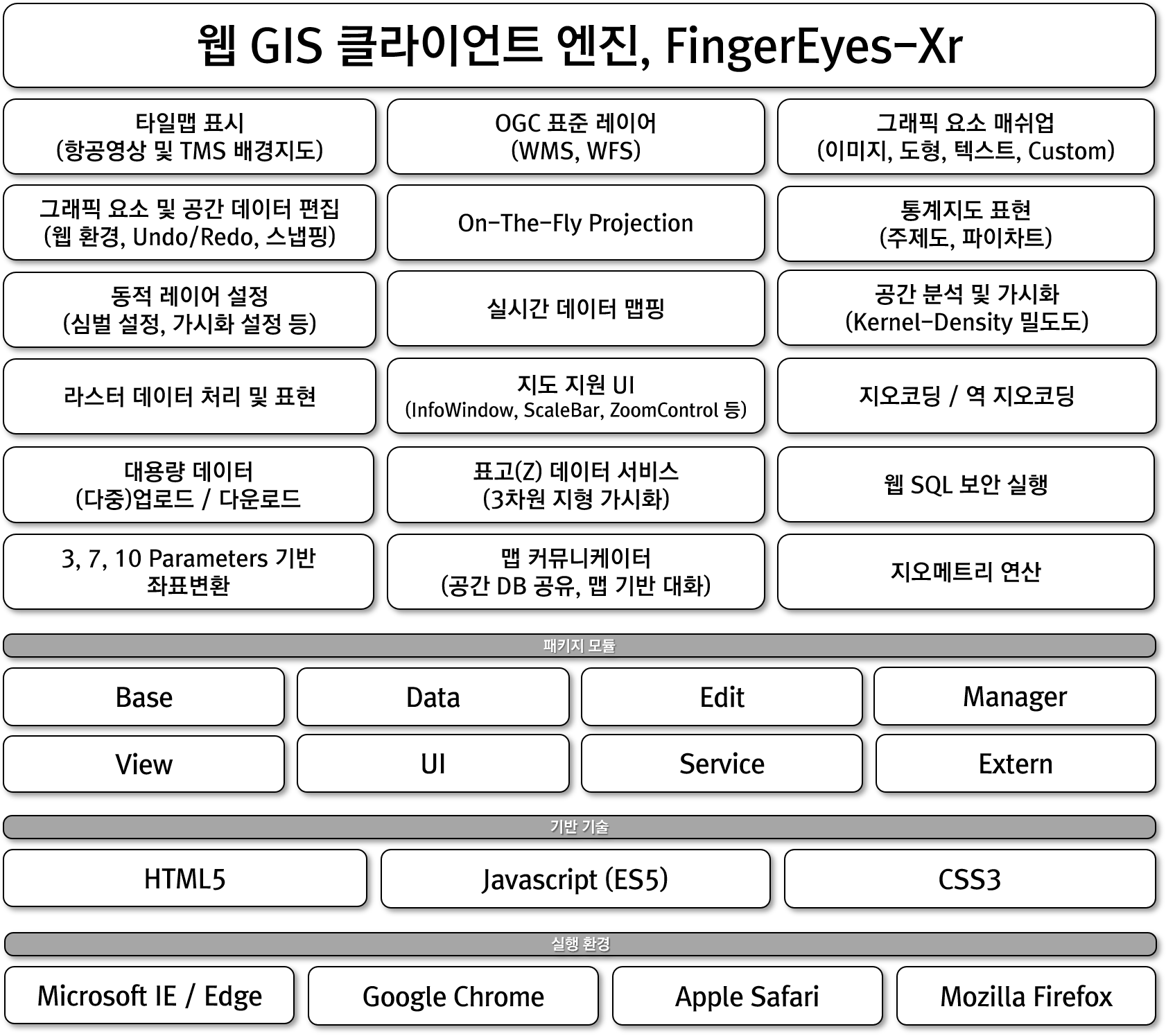
FingerEyes-Xr은 완전한 웹 표준 기술만을 사용하였고, 모든 웹브라우저에서 구현된 표준 기술만을 사용하여 IE, Chrome, Safari, Firefox 등 거의 대부분의 브라우저에서 실행될 수 있습니다. FingerEyes-Xr은 이미 정해진, 구체적인 기능 개발을 지원하는 기반 컴포넌트인데, FingerEyes-Xr에서 지원하는 기능과 이 컴포넌트를 사용해 개발이 가능한 주요 기능은 다음과 같습니다.
먼저 핑거아이즈엑스알(FingerEyes-Xr)은 OGC 표준인 WFS, WMS 방식의 지도를 표시하여 활용할 수 있고, 항공영상을 TMS 방식 등을 통해 배경지도로 활용할 수 있습니다. 그리고 지도 위에 다양한 그래픽 요소를 매쉬업할 수 있는데, 표현할 수 있는 그래픽 요소에는 Marker, Polyline, Polygon, Box, Circle, Ellipse, Text, Image가 있고, 속성 데이터에 기반하여 복합적인 그래픽 요소를 공간 데이터의 차원으로 자유롭게 구성할 수 있는데, 이에 대한 자세한 내용은 아래 글을 참조하시기 바랍니다.
FingerEyes-Xr, 공간 데이터에 대한 Custom Draw (사용자 정의 그리기)
FingerEyes-Xr은 그래픽 요소와 공간 데이터를 웹에서도 자유롭게 편집할 수 있습니다. 이에 대한 구체적인 내용은 FingerEyes-Xr을 이용해 개발된 NexGen의 편집 기능을 통해 확인이 가능하며, 이와 관련된 글은 아래와 같습니다.
넥스젠(NexGen)의 공간 데이터 편집 기능
FingerEyes-Xr은 수치지도와 항공영상과 같은 이미지 지도 뿐만 아니라 라스터(Raster) 기반의 셀 데이터에 대한 연산이 가능하고 그 결과 지도 상에 표현할 수 있습니다. 관련된 내용은 아래와 같습니다.
[GIS] FingerEyes-Xr, 핑거아이즈로 생성한 밀집도(밀도도)
또한 통계 데이터를 주제도와 파이차트 등으로 표현하여 통계지도를 생성할 수 있는데, 이에 대한 간단한 예시는 다음과 같습니다.
FingerEyes-Xr에서 주제도(Theme Map) 표현
FingerEyes-Xr에서 파이 차트(Pie Chart) 표현하기
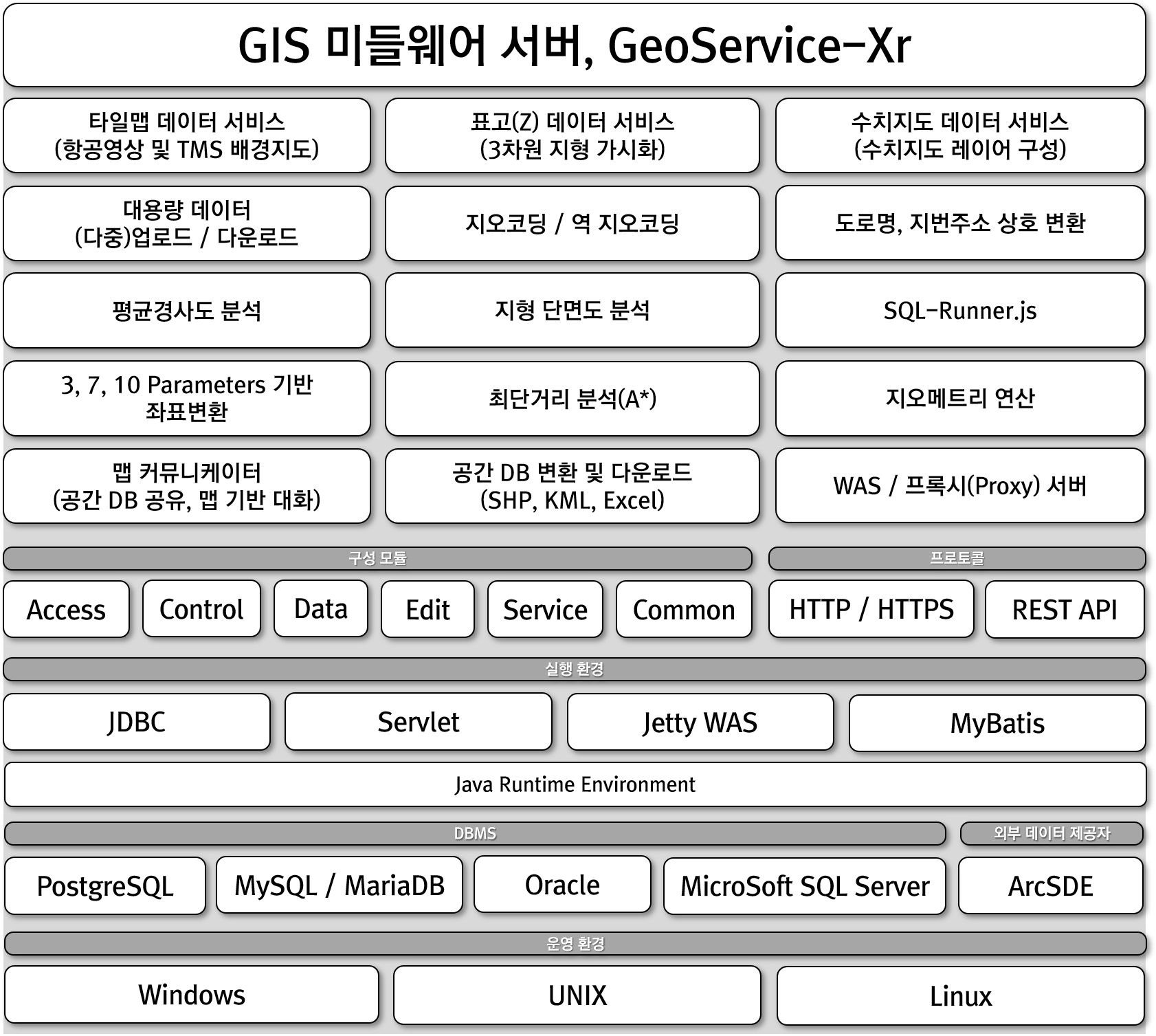
또한 FingerEyes-Xr은 사용자가 보다 쉽게 지도 기반의 기능을 활용할 수 있도록 다양한 지도 관련 UI를 제공하여, 개발자가 쉽게 지도 기반 UI를 구성할 수 있도록 지원합니다. 그리고 GIS 미들웨어 서버인 GeoService-Xr과 연계하여 지오코딩 관련 기능을 제공하며, 관련 내용은 다음과 같습니다.
넥스젠(NexGen)의 스타쿼리(* Query) 기능
그리고 표고값을 이용하여 표고측정, 지형의 표고값을 활용한 지형단면도, 지형 평균경사도, 지형 3차원 가시화 가능을 제공합니다. 이에 대한 내용으로 FingerEyes-Xr을 이용해 개발된 NexGen의 지형 관련 기능은 아래 글과 같습니다.
넥스젠(NexGen)의 DEM 데이터를 활용한 측정 기능
이외에도 FingerEyes-Xr를 이용하여 지도와 관련된 더 많은 기능을 지원하고 있고, 새로운 기능들이 추가되고 있습니다. FingerEyes-Xr을 통해 지도와 관련된 그 어떠한 기능이라도 기술의 제약 없이 개발할 수 있습니다.