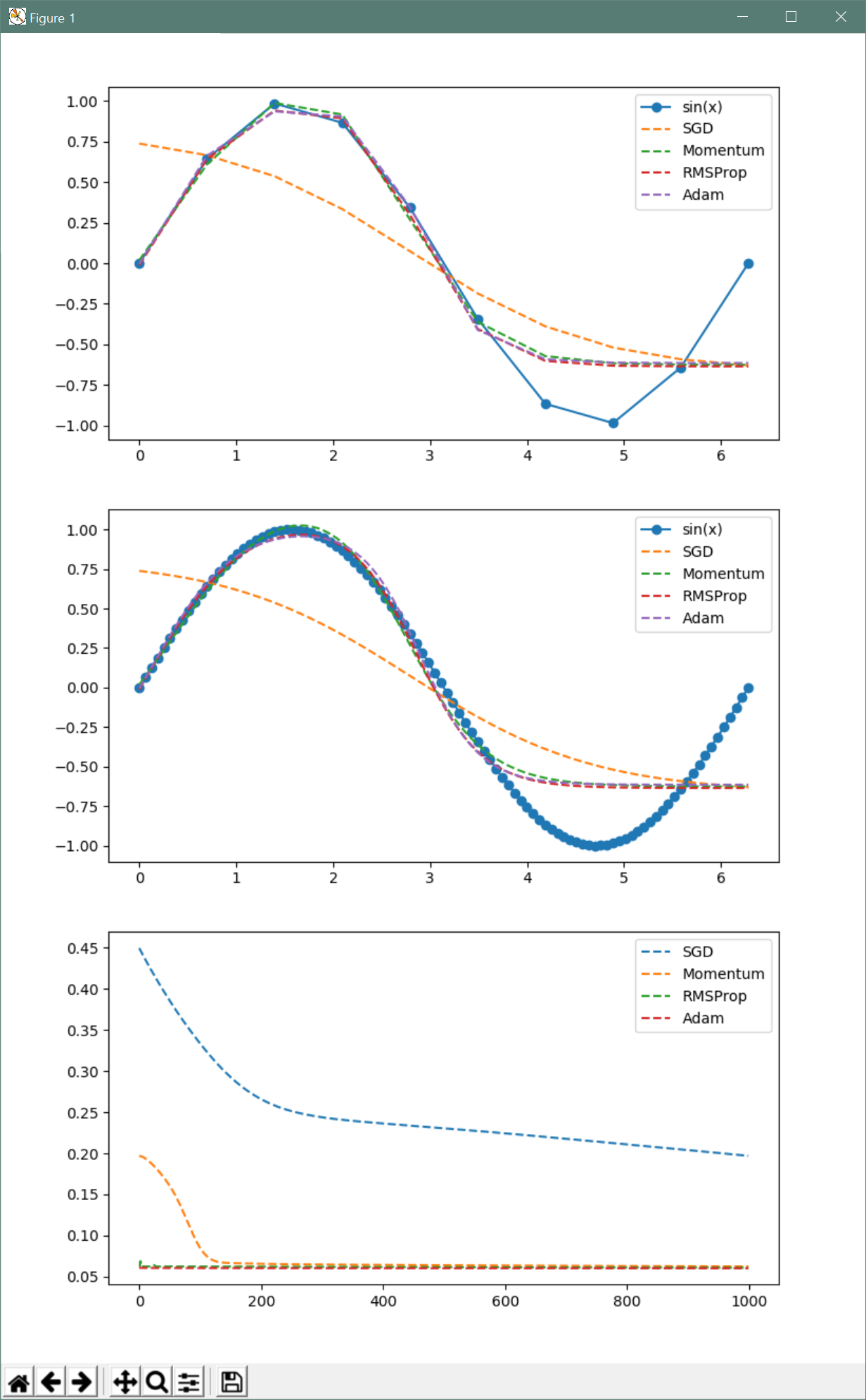
학습 데이터의 특성들은 수치값 뿐만 아니라 ‘크다’, ‘중간’, ‘작다’ 또는 ‘여자’, ‘남자’와 같은 범주값도 존재합니다. 먼저 범주형 값을 처리하기 위해서는 이 범주형 값을 수치값으로 변환해야 합니다. 만약 범주형 값이 ‘A등급’, ‘B등급’, ‘C등급’처럼 그 의미에 순위적 연속성이 존재한다면 그냥 3, 2, 1과 같이 수치값으로 등급을 매칭하면 됩니다. 하지만 ‘여자’, ‘남자’처럼 순위도 연속성도 없다면 반드시 다른 의미로의 수치값으로 변환해야 하는데, 그 변환은 OnHot 인코딩이라고 합니다. 결론을 미리 말하면 ‘여자’라면 벡터 (1,0)으로, 남자라면 (0,1)으로 변경해야 합니다.
샘플 데이터를 통해 이 OneHot 인코딩을 하는 방법에 대해 언급하겠습니다. 샘플 데이터는 아래의 글에서 소개한 데이터를 사용합니다.
먼저 샘플 데이터를 불러옵니다.
import pandas as pd
raw_data = pd.read_csv('./datasets/datasets_1495_2672_abalone.data.csv',
names=['sex', 'tall', 'radius', 'height', 'weg1', 'weg2', 'weg3', 'weg4', 'ring_cnt'])
#names=['성별', '키', '지름', '높이', '전체무게', '몸통무게', '내장무게', '껍질무게', '껍질의고리수']
이 중 sex 컬럼은 성별인데, 이 컬럼의 값을 아래의 코드를 통해 출력해 봅니다.
print(raw_data["sex"][:10])
0 M 1 M 2 F 3 M 4 I 5 I 6 F 7 F 8 M 9 F
범주형 값이라는 것을 알수있는데, M은 숫컷, F는 암컷, I는 유충입니다. 이 sex 컬럼에 대해 OneHot 인코딩 처리를 위해 먼저 문자형을 숫자형으로 변환해주는 OrdinalEncoder 클래스를 통해 처리합니다.
raw_data_labels = raw_data["ring_cnt"].copy()
raw_data = raw_data.drop("ring_cnt", axis=1)
raw_data_cat = raw_data[["sex"]]
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
raw_data_encoded = ordinal_encoder.fit_transform(raw_data_cat)
print(raw_data_encoded[:10])
print(ordinal_encoder.categories_)
[[2.] [2.] [0.] [2.] [1.] [1.] [0.] [0.] [2.] [0.]] [array(['F', 'I', 'M'], dtype=object)]
OrdinalEncoder는 범주형 데이터를 희소행렬(Sparse Matrix)로 그 결과를 반환합니다. 다시 이 희소행렬을 OneHot 인코딩을 시키기 위해 아래의 코드를 수행합니다.
from sklearn.preprocessing import OneHotEncoder onehot_encoder = OneHotEncoder() raw_data_cat_onehot = onehot_encoder.fit_transform(raw_data_cat) print(raw_data_cat_onehot.toarray()[:10]) print(onehot_encoder.categories_)
[[0. 0. 1.] [0. 0. 1.] [1. 0. 0.] [0. 0. 1.] [0. 1. 0.] [0. 1. 0.] [1. 0. 0.] [1. 0. 0.] [0. 0. 1.] [1. 0. 0.]] [array(['F', 'I', 'M'], dtype=object)]
이제 범주형 컬럼인 sex 대신 OneHot 인코딩된 값을 데이터에 추가하도록 합니다.
raw_data = raw_data.drop("sex", axis=1)
raw_data = np.c_[raw_data_cat_onehot.toarray(), raw_data]
print(raw_data[:10])
[[0.0 0.0 1.0 0.455 0.365 0.095 0.514 0.2245 0.100999 0.15 4] [0.0 0.0 1.0 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 2] [1.0 0.0 0.0 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 4] [0.0 0.0 1.0 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 4] [0.0 1.0 0.0 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 2] [0.0 1.0 0.0 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 3] [1.0 0.0 0.0 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 4] [1.0 0.0 0.0 0.545 0.425 0.125 0.768 0.294 0.1495 0.26 4] [0.0 0.0 1.0 0.475 0.37 0.125 0.5095 0.2165 0.1125 0.165 4] [1.0 0.0 0.0 0.55 0.44 0.15 0.8945 0.3145 0.151 0.32 4]]
범주형 타입인 sex가 제거되고 이 sex에 대한 추가적인 3개의 컬럼이 추가되었습니다. 바로 이 3개의 컬럼이 OneHot 인코딩된 값입니다.
이제 수치형 데이터에 대한 스케일링입니다. 여기서 스케일링이란 서로 다른 특성들을 일정한 값의 범위로 맞춰주는 것입니다. 흔히 사용하는 방식은 Min-Max 스케일링과 표준화(Standardization)이 있습니다. 먼저 Min-Max 스케일링은 특징의 최소값과 최대값을 먼저 계산하고 이 값을 이용하여 전체 특징값들을 0~1 사이의 값으로 변경시킵니다. 표준화는 먼저 평균과 표준편차를 구하고 전체 데이터 각각에 대해 평균을 뺀 후 표준편차로 나눠 분산이 1이 되도록 데이터를 조정합니다. 각각 sklearn에서 제공하는 MinMaxScaler와 StandardScaler 클래스를 통해 수행이 가능합니다. 아래의 코드는 Min-Max 스케일링을 수행하는 코드입니다.
from sklearn.preprocessing import MinMaxScaler minmax_scaler = MinMaxScaler() raw_data = minmax_scaler.fit_transform(raw_data) print(raw_data[:10])
[[0. 0. 1. 0.51351351 0.5210084 0.0840708 0.18133522 0.15030262 0.1323239 0.14798206 0.75 ] [0. 0. 1. 0.37162162 0.35294118 0.07964602 0.07915707 0.06624075 0.06319947 0.06826109 0.25 ] [1. 0. 0. 0.61486486 0.61344538 0.11946903 0.23906499 0.17182246 0.18564845 0.2077728 0.75 ] [0. 0. 1. 0.49324324 0.5210084 0.11061947 0.18204356 0.14425017 0.14944042 0.15296462 0.75 ] [0. 1. 0. 0.34459459 0.33613445 0.07079646 0.07189658 0.0595158 0.05134957 0.0533134 0.25 ] [0. 1. 0. 0.47297297 0.41176471 0.0840708 0.12378254 0.09414929 0.10138249 0.1180867 0.5 ] [1. 0. 0. 0.61486486 0.60504202 0.13274336 0.27465911 0.15870881 0.18564845 0.32735426 0.75 ] [1. 0. 0. 0.63513514 0.62184874 0.11061947 0.27129449 0.19704102 0.1961817 0.25759841 0.75 ] [0. 0. 1. 0.54054054 0.52941176 0.11061947 0.17974146 0.14492266 0.14746544 0.16292975 0.75 ] [1. 0. 0. 0.64189189 0.64705882 0.13274336 0.31609704 0.21082717 0.19815668 0.31738914 0.75 ]]
결과를 보면 전체 데이터가 모두 0~1 사이의 값으로 변환된 것을 알 수 있습니다.