
상관관계는 특정 특성에 대해 다른 특성들이 얼마나 영향을 주는지에 대한 척도라고 할 수 있습니다. 가장 흔히 사용되는 상관관계 조사는 표준 상관계수(Standard Correlation Coefficient)로 판다스의 corr 매서드를 통해 쉽게 얻을 수 있습니다.
글의 진행을 위해 사용한 샘플 데이터에 대한 소개는 아래 글을 참고하기 바랍니다.
아래의 코드는 샘플 데이터의 특성 중 ring_cnt에 영향을 주는 다른 특성의 표준 상관계수를 구해 출력합니다.
import pandas as pd
raw_data = pd.read_csv('./datasets/datasets_1495_2672_abalone.data.csv',
names=['sex', 'tall', 'radius', 'height', 'weg1', 'weg2', 'weg3', 'weg4', 'ring_cnt'])
corr_matrix = raw_data.corr()
print(corr_matrix["ring_cnt"].sort_values(ascending=False))
결과는 다음과 같습니다.
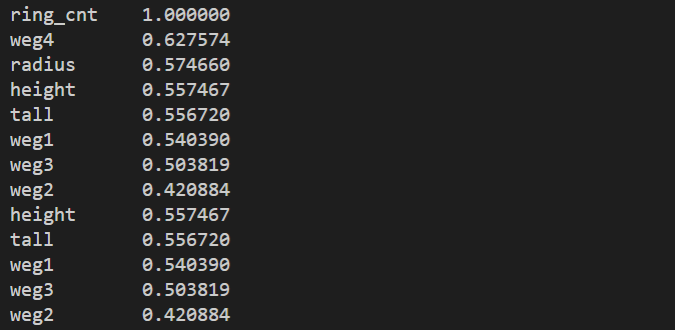
표준상관계수는 특성간의 선형적인 관계를 추출해줍니다. 즉, 선형적으로 비례하면 기울기 1에 가깝고 반비례하면 기울기 -1에 가깝습니다. 선형적으로 관계가 약하면 0에 가깝게 됩니다. 위의 결과를 보면 ring_cnt 특성 중 weg4가 가장 큰 선형 관계를 가지지만 다른 특성 역시 비슷한 선형적 관계를 가지고 있습니다.
아래의 코드처럼 상관관계 조사를 위해 각 특성들을 1:1로 매칭(x축, y축)으로 분포도를 쉽게 출력하여 시각적으로 상관관계를 파악할 수 있습니다.
from pandas.plotting import scatter_matrix scatter_matrix(raw_data) plt.show()
결과는 다음과 같습니다.
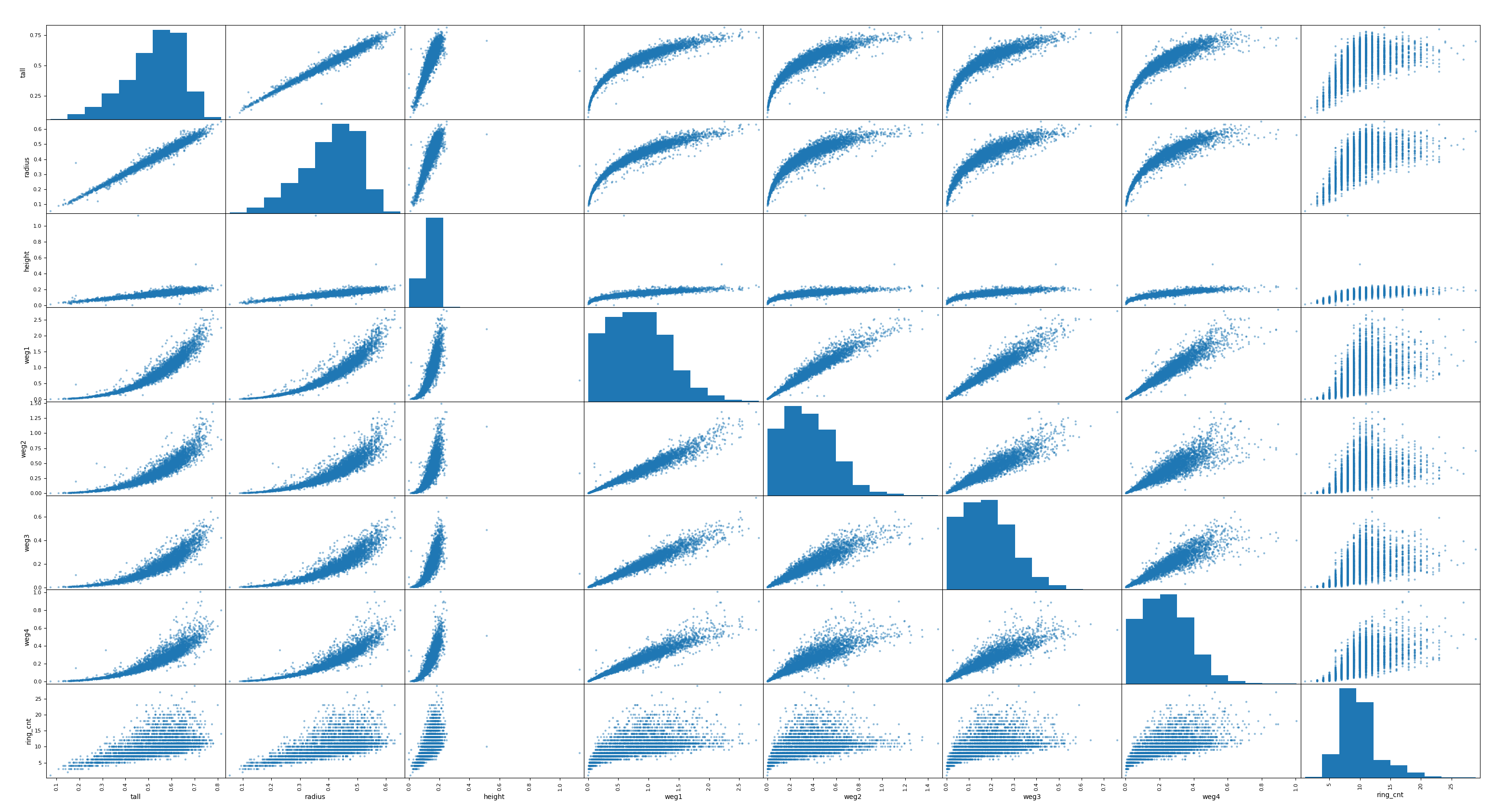
동일한 특성에 대한 그래프는 아차피 기울기가 1인 선형이므로 히스트그램으로 표시됩니다. ring_cnt를 X축으로 하는 다른 그래프를 살펴보면 height 특성을 제외하고 매우 밀접한 상관관계를 갖고 있음을 알 수 있습니다. 이는 표준 상관계수에서 파악하지 못한 내용입니다.