
AutoEncoder는 학습 데이터에 레이블 데이터를 별도로 구축할 필요가 없는, 주어진 데이터만으로 학습이 가능한 비지도 학습 신경망입니다. 엄밀히 말해 입력 데이터가 곧 레이블 데이터가 됩니다. AutoEncoder 신경망은 Encoder와 Decoder라는 2개의 신경망으로 구성됩니다. Encoder는 입력 데이터에서 중요한 정보만을 남기고 신경망의 입장에서 학습시에 중요하지 않다고 판단되는 정보는 제거함으로써 처음 입력 데이터의 크기보다 더 작은 크기의 데이터(z)를 생성해 주는 신경망입니다. Decoder는 Encoder가 생성한 z를 가지고 다시 처음의 입력 이미지로 복원하는 신경망입니다.
Encoder가 생성해 주는 보다 더 작은 크기의 데이터를 잠재 벡터(Latent Vector)이라고 하며, z라고 흔히 표기합니다. 이 z는 GAN의 Generator의 입력 데이터인 z와 그 의미가 동일선상에 놓여 있습니다. 잠재 벡터라고 하는 이유는 어떤 중요한 ‘의미’가 잠재되어 있는 데이터(벡터)이기 때문입니다. 결국 이 z에는 처음 입력 데이터에서 중요한 의미만을 남겨 놓은 것, 압축된 것이라고 할 수 있습니다. 또한 이 z에는 별로 중요하지 않거나 잡음같은 것들이 제거된 데이터라고 할 수 있습니다. 압축 차원에서 보자면 손실 압축입니다. 이러한 AutoEncoder 신경망의 용도는 차원감소, 중요한 의미 추출, 잠재벡터를 통한 복잡한 데이터의 공간상 시각화, 이미지 검색, Segmentation, Super Resolution 등 매우 다양합니다.
이러한 AutoEncoder를 이미지 압축과 복원의 관점에서 CNN 레이어를 사용해 구현함으로써 더욱 구체적인 내용을 정리해 보겠습니다. 딥러닝 라이브러리는 PyTorch를 사용하였습니다. TensorFlow 역시 신경망 구성 레이어는 동일하니 어렵지 않게 변환이 가능할 것입니다.
먼저 필요한 패키지들을 Import 해 둡니다.
import torch import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler import torchvision.datasets as dset import torchvision.transforms as transforms import matplotlib.pyplot as plt import random from torch.utils.data import DataLoader
압축과 복원 대상이 되는 이미지는 Fashion MNIST를 사용하겠습니다.
batch_size = 1024 root = './MNIST_Fashion' transform = transforms.Compose([transforms.ToTensor()]) train_data = dset.FashionMNIST(root=root, train=True, transform=transform, download=True) test_data = dset.FashionMNIST(root=root, train=False, transform=transform, download=True) train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True) test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, drop_last=True)
AutoEncoder의 신경망에 대한 클래스를 정의합니다.
z_size = 314
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=2, stride=2, bias=False),
nn.LeakyReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=2, stride=2, bias=False),
nn.LeakyReLU(),
Reshape((-1,7*7*64)),
nn.Linear(7*7*64, z_size),
nn.LeakyReLU(),
)
self.decoder = nn.Sequential(
nn.Linear(z_size, 7*7*64),
nn.LeakyReLU(),
Reshape((-1,64,7,7)),
nn.ConvTranspose2d(in_channels=64, out_channels=32, kernel_size=2, stride=2, bias=False),
nn.LeakyReLU(),
nn.ConvTranspose2d(in_channels=32, out_channels=1, kernel_size=2, stride=2, bias=False),
nn.Sigmoid()
)
def forward(self, x):
out = self.encoder(x)
out = self.decoder(out)
return out
위의 코드가 기술하는 신경망의 구성 레이어들 사이로 전달되는 Tensor의 크기를 표기한 그림은 다음과 같습니다.
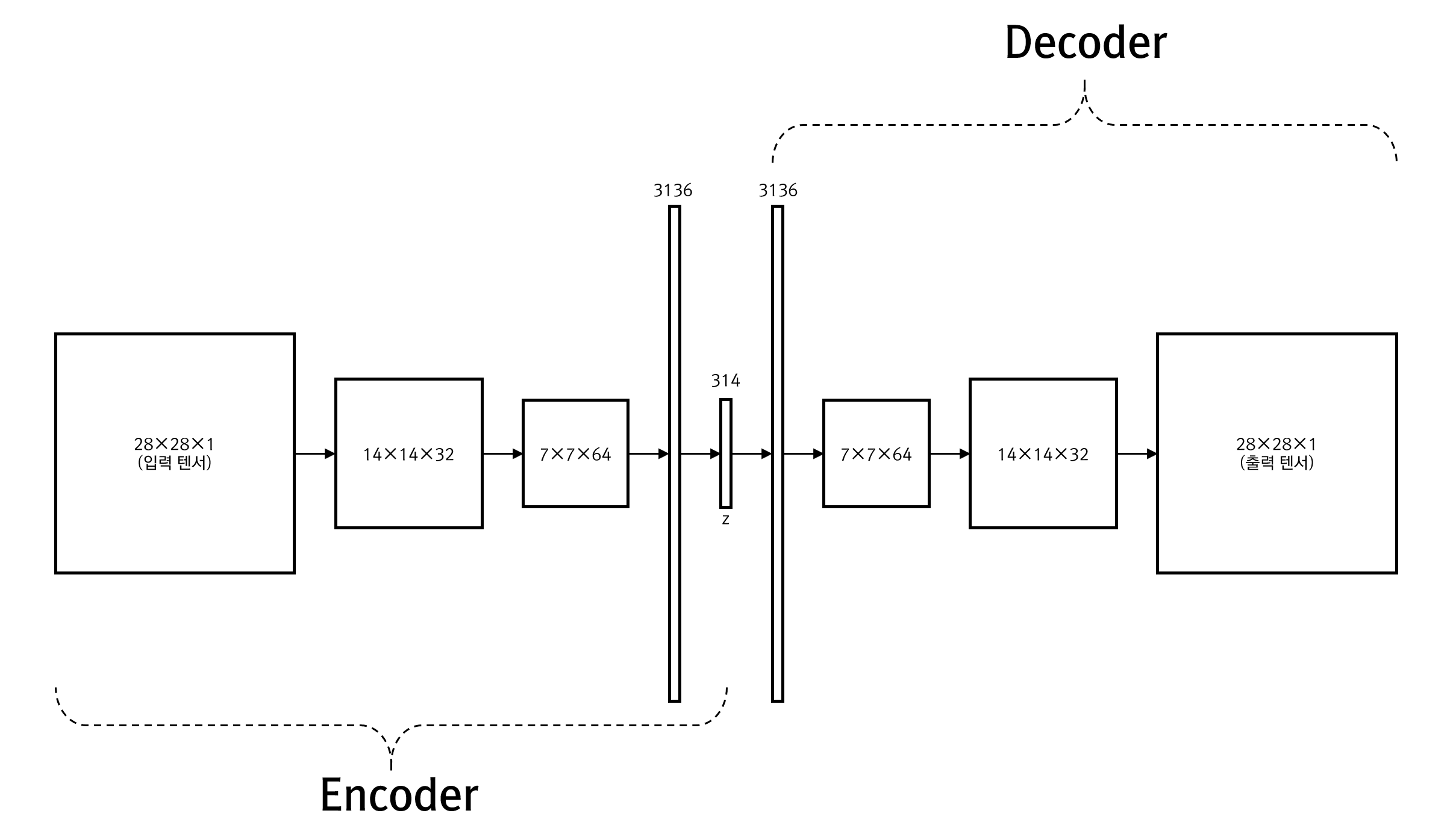
AutoEncoder 클래스는 encoder와 decoder로 레이어들을 분리해 구성하고 있는 것을 볼 수 있습니다. 이렇게 해두면 추후에 encoder 만을 이용해 잠재 벡터만을 쉽게 얻어낼 수 있습니다. 보시면 encoder와 decoder는 레이어의 구성이 성호 대칭성이 있는 것을 볼 수 있습니다. 또한 앞서 언급 했듯이 AutoEncoder는 입력 데이터가 레이블 데이터로 사용되므로 출력 데이터가 입력 데이터의 텐서 크기와 동일합니다. 중요한 점은 z의 크기인 z_size를 314로 해두었는데, 이는 원본 이미지의 크기 28×28인 784가 약 40%의 크기로 압축된다는 것입니다. 다시 상기하면 이 40% 크기로 압축된 z에는 원본 이미지의 중요한 특징값들이 잠재되어 있고 불필요한 것이라고 판단되는 것들은 제거되어 있다는 것입니다. 물론 이러한 판단은 신경망이 데이터를 통해 스스로 판단합니다.
추가적으로 위의 신경망 클래스의 구성 레이어 중 Reshape라는 Tensor의 크기를 변경해 주는 레이어의 코드는 다음과 같습니다.
class Reshape(nn.Module):
def __init__(self, shape):
super(Reshape, self).__init__()
self.shape = shape
def forward(self, x):
return x.view(*self.shape)
다음은 학습 코드입니다.
num_epochs = 15
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoEncoder().to(device)
loss_func = nn.MSELoss().to(device)
optimizer = optim.Adam(model.parameters())
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer,threshold=0.1, patience=1, mode='min')
for i in range(num_epochs):
for _, [image, _] in enumerate(train_loader):
x = image.to(device)
y_= image.to(device)
optimizer.zero_grad()
output = model(x)
loss = loss_func(output, y_)
loss.backward()
optimizer.step()
scheduler.step(loss)
print('Epoch: {}, Loss: {}, LR: {}'.format(i, loss.item(), scheduler.optimizer.state_dict()['param_groups'][0]['lr']))
몇차례 실행을 해보니 15 Epoch 정도에서 손실값이 더 이상 감소하지 않는 것을 확인했고 Overfitting을 방지하기 위해 최종적으로 반복 학습수를 15로 지정했습니다. 물론 어떤 신경망은 학습시에 손실값이 한동안 일정값에서 정체 하다가 다시 감소하는 경우가 있으므로 지속적이고 세밀한 관찰이 필요합니다.
학습이 완료되었다면, 그 결과를 시각화합니다.
model.eval()
rows = 4
for c in range(rows):
plt.subplot(rows, 2, c*2+1)
rand_idx = random.randint(0, test_data.data.shape[0])
plt.imshow(test_data.data[rand_idx].view(28,28), cmap='gray')
plt.axis('off')
plt.subplot(rows, 2, c*2+2)
inp = transform(test_data.data[rand_idx].numpy().reshape(28,28)).reshape(1,1,28,28).to(device)
img = model(inp)
plt.imshow(img.view(28,28).detach().cpu().numpy(), cmap='gray')
plt.axis('off')
print(test_data.targets[rand_idx])
plt.show()
결과는 아래와 같습니다.

총 4줄의 이미지들이 표시되는데, 왼쪽은 입력 이미지이고 오른쪽은 AutoEncoder의 Decoder가 생성해낸 이미지입니다.