HTML5에서 제공하는 기능 중 File API가 있습니다. 로컬에 저장된 파일을 읽을 때 사용되는 API입니다. ArrayBuffer와 DataView와 함께 사용하여 바이너리(Binary) 데이터를 읽을 수 있습니다. 특히나 로컬에 저장된 물리적인 파일을 File이라는 클래스를 통해 접근할 수 있는데요. 이 File은 Blob를 상속받으며, 이 Blob의 slice 함수를 사용하면 대용량의 파일 전체 내용을 메모리에 올리지 않고도 필요한 부분만을 올려 사용할 수 있다는 매우 큰 장점을 갖습니다.
이 글은 이러한 HTML5의 기능 중 하나인 File API에 대한 설명을 예제를 통해 살펴보도록 하겠습니다. 먼저 File API를 사용하기 위해서는 읽을 파일을 지정해야 하는데, 보안상의 이유로 사용자가 특정한 행위를 통해 지정된 파일만을 제한하여 사용할 수 있습니다. 여기서 말하는 사용자의 특정 행위는 2가지로 다음과 같습니다.
- 파일 선택 대화상자를 통해 읽을 파일을 사용자가 선택
- 사용자가 드래그 앤 드랍(Drag & Drop)으로 읽을 파일을 선택
여기서는 파일 선택 대화상자를 통해 읽을 파일을 사용자가 선택하는 방법으로 File API에 대해 살펴보도록 하겠습니다. 파일 선택 대화상자를 웹에서 사용하기 위해서는 다음의 코드에서 2번째줄의 HTML Tag가 필요합니다.
<body onload="load()">
<input type="file" id="inputFile" accept=".dbf" />
</body>
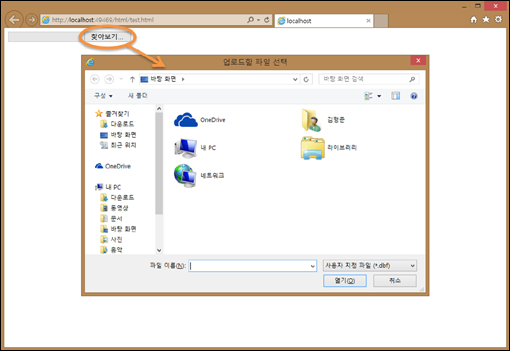
즉, TYPE 속성이 file인 INPUT 테그를 사용하는데요, accept 속성을 이용해 선택할 파일의 확장자에 대한 필터링을 지정할 수 있습니다. 아울러 multiple 속성을 지정하면 파일을 여러개를 다중으로 선택할 수 있습니다. 실행해 보면 다음과 같은 결과를 볼 수 있는데요, 찾아보기 버튼을 클릭하여 파일 선택 대화상자까지 표시한 상태입니다.
앞서 코드에서 1번 줄을 보면 BODY에 onload 이벤트에 대해 load() 함수가 지정된 것을 볼 수 있습니다. 이 load() 함수에 대한 코드는 다음과 같습니다.
function load() {
if(!(File && FileReader && FileList && Blob)) {
alert("Not Supported File API");
}
document.getElementById("inputFile").onchange = function () {
var file = this.files[0];
var name = file.name;
var size = file.size;
var reader = new FileReader();
reader.onload = function () {
var aBuf = this.result; // ArrayBuffer
var dView = new DataView(aBuf);
var validFlag = dView.getUint8(0);
var year = dView.getUint8(1);
var month = dView.getUint8(2);
var day = dView.getUint8(3);
var numRecords = dView.getInt32(4, true);
var numHeaders = dView.getInt16(8, true);
};
var blob = file.slice(0, 1000);
reader.readAsArrayBuffer(blob);
};
}
코드는 짧지만 상당히 많은 내용을 담고 있습니다. 하나 하나 살펴보면 다음과 같습니다.
2번 코드는 해당 웹브라우저가 File API를 지원하는지 검사합니다. 전역 객체로써 window에 대해 File API에서 제공하는 속성은 File, FileReader, FileList, Blob 정도입니다. 그리고 6번 코드는 앞서 파일 선택 대화상자를 통해 파일을 지정했을때 발생하는 이벤트인 onchange에 대한 함수를 지정하고 있습니다. 7번 코드에서는 사용자가 선택한 파일을 File 타입의 객체를 얻습니다. 그리고 이 객체를 통해 파일명, 파일크기를 각각 8번과 9번 코드를 통해 얻을 수 있습니다. 10번 코드에서 생성한 FileReader 객체는 실제 파일의 내용을 읽어와 해석(Parsing)하기 위해 사용하는 객체입니다. 12번 코드에서는 이 FileReader 객체의 onload 이벤트 함수를 지정하고 있는데요. 바로 이 onload 이벤트 함수가 실행되는 시점은 실제 물리적인 파일로부터 데이터를 메모리에 모두 성공적으로 올릴 때입니다. 여기서 중요한 부분은 실제 물리적인 파일로부터 데이터를 메모리에 올릴때, 파일의 내용 전체를 올릴 수도 있고 위의 예제처럼 파일의 시작에서부터 총 1000바이트만을 올릴 수도 있다는 것입니다. 26번 코드가 바로 파일의 시작에서부터 총 1000바이트를 올리기 위해 BLOB 객체를 생성한 것입니다. 27번 코드는 이 BLOB 객체를 통해 실제 메모리에 올리라는 함수 호출인데요, 이 함수의 이름(readAsArrayBuffer)처럼 메모리에 올린 데이터를 ArrayBuffer 타입으로 처리할 수 있도록 합니다. 이미 언급했듯이 성공적으로 메모리에 지정한 데이터를 올리게 되면 12번 코드에서 지정한 onload 이벤트가 호출됩니다. 이 onload 이벤트에 지정한 함수를 살펴보면, 먼저 13번 코드에서 메모리에 올린 데이터(청크(Chunk)라고 함)를 ArrayBuffer 타입의 객체로 얻습니다. 그리고 이 ArrayBuffer 객체를 이용하여 DataView 타입의 객체를 생성합니다. 이처럼 ArrayBuffer에서 DataView로 변경하는 이유는 DataView가 메모리 덩어리로부터 쉽게 원하는 타입의 값을 읽어올 수 있는 함수를 제공하기 때문입니다. 바로 16번 코드에서부터 21번 코드에서 보이는 getUint8이나 getInt32 그리고 getInt16인데요. 이 함수는 1개 또는 2개의 인자를 갖습니다. 공통적으로 첫번째 인자는 메모리에 올라간 데이터에서 읽어올 위치이고 두번째는 2바이트 이상의 데이터를 읽어왔을 경우에 엔디안(Endian) 처리를 어떻게 할 것인가 입니다. 이 인자를 지정하지 않거나 false로 지정하면 Big Endian인데, 위의 예제에서는 true를 주어 Little Endian으로 해석하라고 지시하고 있습니다.
이처럼 HTML5에서 제공하는 File API를 이용하여 바이너리(Binary) 차원에서 원하는 데이터를 원시 타입 단위로 읽어올 수 있는 것을 볼 수 있습니다. HTML5의 File API, 참으로 멋진 기능입니다.