늦깍이에 웹 개발의 험난한 파도 속에 허욱적 대고 있는 요즘.. jQuery에서 가장 많이 사용하는 선택자가 까마귀 고기로 보여 컨닝 페이퍼 만들어 봅니다.
전체 선택자
$('*').css('color', 'red');
Tag 선택자
$('h1').css('color', 'orange');
ID 선택자
$('#abc').css('color', 'orange');
여러 개의(OR 조건) 선택자
$('h1, p, #abc').css('color', 'orange');
class 선택자
$('.item').css('color', 'black');
AND 조건 선택자
$('.item.abc').css('color', 'black');
자식 선택자
$('div > p').css('color', 'black');
후손 선택자
$('div p').css('color', 'black');
속성 선택자
$('h1[tt').val('good'); // 속성을 가지는 것 선택
$('h1[tt=aa').val('good'); // 속성값 일치하는 것 선택
$('h1[tt~=aa').val('good'); // 속성값에 단어로써 포함하는 것 선택
$('h1[tt^=aa').val('good'); // 속성값의 시작에 일치하는 것 선택
$('h1[tt$=aa').val('good'); // 속성값의 끝에 일치하는 선택
$('h1[tt*=aa').val('good'); // 속성값에 포함하는 것 선택
$('.a:checked').val('good'); // checked된 input 요소
$('.a:disabled').val('good'); // 비활성화된 input 요소
$('.a:enabled').val('good'); // 활성화된 input 요소
$('.a:focus').val('good'); // 포커스 대상 input 요소
$('.a:input').val('good'); // input, textarea, button, select 요소
alert( $('.a > option:selected').val() ); // class 'a'를 가진 select 요소 자식 중 선택된 option 요소
var myArray = [1, 2, 3, 4, 5];
if ($.inArray(4, myArray) !== -1) {
alert('found.');
}
다음은 어떤 객체에 또 다른 객체의 키-값을 복사해 주는 플러그인입니다. $.extend의 첫번째 인자는 복사가 되어 값이 저장될 대상 객체입니다. 그리고 두번째 이후의 인자는 복사될 키-값을 담고 있는 객체들입니다. 아래의 코드는 secondObj의 키-값을 firstObj에 복사해 주는 코드인데요. 결국 firstObj.foo는 secondObj.foo의 값으로 변경됩니다. $.extend는 첫번째 인자를 반환하므로 newObject === firstObj는 true입니다.
var firstObj = { foo: 'bar', a: 'b' };
var secondObj = { foo: 'baz' };
var newObject = $.extend(firstObj, secondObj);
alert(firstObj.foo);
if (newObject === firstObj) {
alert('equal');
}
다음 코드는 함수 호출시 내부의 this를 개발자가 의도한 객체로 하여 함수를 호출하도록 하는 플러그인입니다. 아래의 코드에서 myFunction는 전역 객체인 Window의 소유로 이 함수를 그대로 호출하면 함수 내부에서 this는 Window 객체가 됩니다. 그러나 12번 코드를 통해 myFunction 함수에 대한 내부 this를 myObject로 변경해주는 함수로 myProxyFunction를 생성하고 있습니다. 실제로 이 myProxyFunction를 13번 코드처럼 그대로 호출하면 함수 내부의 this는 myObject가 됩니다. JavaScript의 이벤트 리스너 함수에서 this 객체가 다소 혼란스러울 때가 있습니다. 이 혼란의 시기에 이 플러그인이 해결점이 될 수 있겠습니다.
var myFunction = function () {
alert(this);
};
var myObject = {
foo: 'bar',
toString: function () { return 'myObject'; }
};
myFunction();
var myProxyFunction = $.proxy(myFunction, myObject);
myProxyFunction();
다음은 배열을 순회하면서 원하는 값들로 구성된 배열을 생성하는 플러그인입니다. 7번 코드의 실행을 통해 arr 배열의 요소 객체의 id 속성만으로 구성된 배열을 생성해 반환합니다. 11번 코드는 새롭게 생성된 배열의 값을 확인하는 코드입니다.
var arr = [
{ id: 'a', tagName: 'li' },
{ id: 'b', tagName: 'li' },
{ id: 'c', tagName: 'li' }
];
var result = $.map(arr, function (value, index) {
return value.id;
});
$.each(result, function (i, v) {
alert(i + ' : ' + v);
});
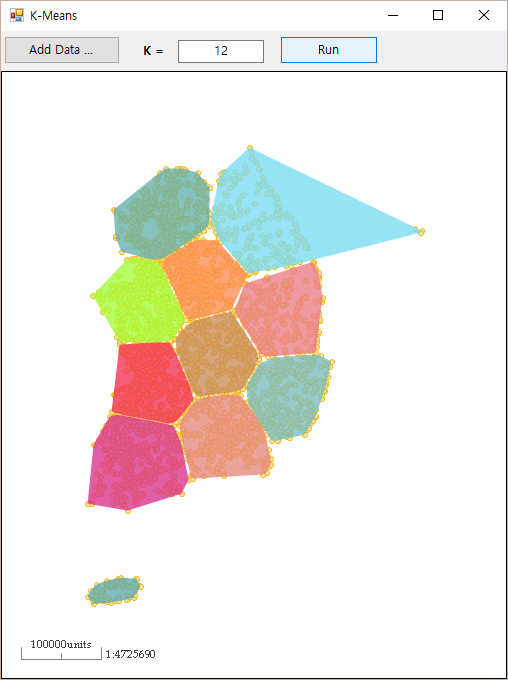
군집화 알고리즘(Clustering Algorithm) 중 K-Means 가 있습니다. K-Means 알고리즘에 대한 설명 이전에, 실제로 구현된 K-Means 알고리즘에 대한 실행 결과를 바로 설명하면서 자연스럽게 K-Means 알고리즘이 무엇인지 설명하겠습니다. 아래는 K-Means 알고리즘을 실행하기 위해 입력한 포인트 데이터입니다. SHP 파일을 통해 입력 받았습니다.
위의 이미지처럼 공간상에 무수히, 주관적 해석이긴 하지만 의미 없이 분포되어 있는 포인트들에 대해서 어떤 연관 관계에 대한 특성을 부여함으로써 몇개로 묶을 수 있는데요. 이처럼 묶는다라는 것을 그룹핑, 클러스터링이라고 합니다. K-Means 알고리즘에서 몇개(K개)로 묶을지를 지정하여 원하는 개수 만큼 클러스터링할 수 있습니다. 아래의 화면은 K-Means 알고리즘을 활용하여 12개의 그룹으로 공간상의 포인트를 묶은 결과입니다.
앞서 포인트를 그룹으로 묶을 때 어떤 관계에 대한 특성을 부여한다고 하였는데요. 위의 화면에서는 그 특성을 거리(Distance)로 하였습니다. 즉, 거리 상으로 가까운 포인트들을 그룹으로 묶는 것입니다.
이처럼 이미 확보한 수 많은 공간상의 데이터를 그룹핑하여 놓는다면, 새로운 포인트에 대해서 어느 그룹에 포함되는지에 대한 해석이 매우 빠르게 분류될 수 있습니다. 이미 확보한 데이터가 많으면 많을 수록, 새로운 데이터에 대한 해석이 보다 더 정확할 수 있겠죠.
아래는 K-Means 알고리즘을 구현한 C# 소스코드이며, 듀라맵(DuraMap-Xr)을 이용하여 K-Means 알고리즘에 필요한 포인트 데이터를 SHP 파일로부터 읽어 들이고 그 결과를 시각화 하였습니다.