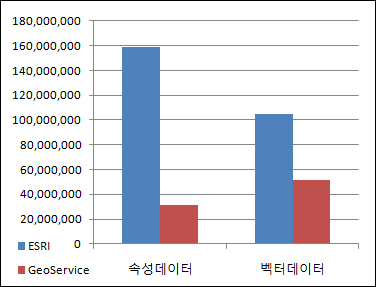
이 문서는 MySQL을 설치하면 제공되는 터미널 모니터의 사용법을 간단히 정리한 것입니다. 가장 먼저 서버에 연결하는 방법은 아래와 같습니다.
c:\>mysql -h localhost -u root -p
Enter password: ******
쉘에서 mysql 명령을 통해 인자 -h에는 호스트(여기서는 localhost를 지정했으며 로컬일때는 생략이 가능)를 제공하며 -u에는 사용자의 ID(여기서는 root)를 제공하고 마지막으로 -p 옵션을 주어 패스워드를 입력받을 수 있도록 합니다.
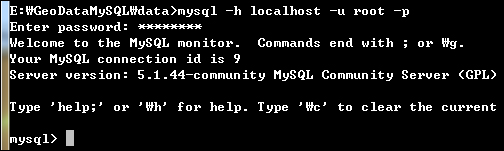
패스워드를 올바르게 입력하고 모든 것이 성공하면 위의 그림처럼 mysql>가 뜨고 명령을 입력할 수 있는 상태가 됩니다. 참고로 연결을 끊는 방법은 quit 명령을 내려 종료할 수 있습니다.
시험 삼아 다음 명령을 내려 MySQL의 기능을 테스트해 보도록 하겠습니다.
SELECT VERSION(), CURRENT_DATE;
SELECT SIN(PI()/4), (4+1)*4;
SELECT NOW();
이 세 명령에 대한 결과는 아래와 같습니다.
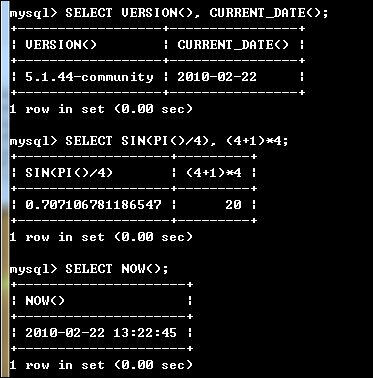
참가로 명령어 입력 도중에 취소를 하고자 한다면 \c를 입력하고 엔터키를 누르면 됩니다. 정리하면 명령어는 대소문자를 구분하지 않으며 끝은 반드시 ; 으로 끝나야 합니다.
이제 다음은 데이터베이스를 생성하는 명령입니다.
CREATE DATABASE XrGeoDatabase
지금까지 생성되어진 데이터베이스의 목록을 살펴보는 명령은 다음과 같습니다.
SHOW DATABASES;
이 데이터베이스 중에 사용할 데이터베이스를 선택하는 명령은 다음과 같습니다.
USE XrGeoDatabase;
아래는 위에서 새롭게 보인 세개의 명령을 순차적으로 내려 MySQL에서 처리된 결과 화면입니다.
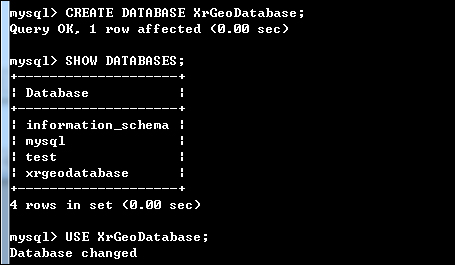
데이터베이스에 대한 명령으로써 삭제에 대한 것은 아래와 같습니다.
DROP DATABASE XrGeoDatabase;
이제 데이터베이스를 선택했고 이 선택한 데이터베이스 안에 테이블을 생성하는 명령은 아래와 같습니다.
CREATE TABLE tablename (
column_name1 INT,
column_name2 VARCHAR(15),
column_name3 INT );
테이블이 잘 생성되었는지 선택된 데이터베이스에 존재하는 테이블의 목록을 살펴보는 명령은 다음과 같습니다.
SHOW TABLES;
특정 테이블에 대한 테이블 스키마를 살펴보는 명령은 다음과 같습니다.
EXPLAIN tablename;
아래의 그림은 위의 세가지 명령을 순서대로 수행한 것에 대한 화면의 결과입니다.
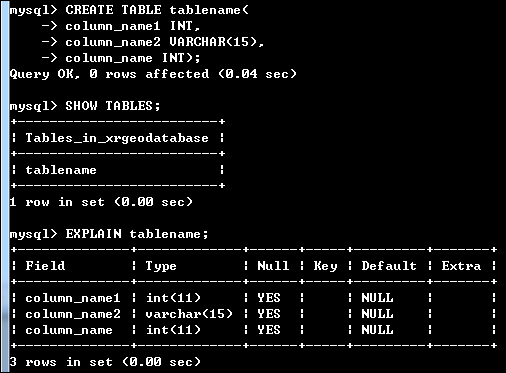
참고로 테이블의 이름을 변경하는 명령은 다음과 같습니다.
RENAME TABLE tablename TO other_tablename;
그리고 필요하지 않은 테이블을 삭제하는 명령은 다음과 같습니다.
DROP TABLE tablename;
MySQL은 사용자가 작업하는 과정의 상태 정보를 제공하기 위해 status 명령을 제공합니다. 또한 명령 처리에 대해 오류나 경고가 발생할 경우 그 메세지를 다시 보기 위해 show errors와 show warnings 명령을 제공합니다.
이외에 데이터를 쿼리하고 레코드를 추가하고 변경하는 등의 SQL문에 대해 간단한 예를 통해 보이고 마무리 하겠습니다.
테이블로부터 지정한 필드들에 대한 값을 쿼리하는 명령
SELECT col1, col2 FROM tablename;
레코드를 추가하는 명령
INSERT INTO tablename VALUES (value1, value2);
조건에 맞는 레코드의 값을 변경하는 명령
UPDATE tablename SET col1=newValue WHERE col2=value;
레코드를 삭제하는 명령
DELETE FROM tablename WHERE col2=value;