
의미적으로 같은 성질의 데이터들을 공간상에 분포시켜 가시화해 본다면, 같은 의미를 가지는 데이터들은 공간 위치상으로 한곳에 모여있을 것입니다. 이렇게 데이터를 공간상에 분포시켜 놓을 수 있다면 해석 결과로써의 데이터가 얼마나 잘 해석되었는지를 시각화할 수 있고, 새로운 데이터에 대한 공간상의 위치를 통해 어떤 성질군에 해당하는지를 시각적으로 쉽게 파악할 수 있습니다.
그러나 문제는 사람이 인지하는 공간은 2차원 또는 3차원이라는 점이고, 데이터는 이보다 더 큰 차원을 갖는다는 것이 일반적입니다. 만약 3차원보다 큰 다 차원의 데이터에 대해 어떤 유사도 값이 있다고 할때, 이 유사도와 비슷한 2차원 또는 3차원의 데이터를 얻을 수 있도록 학습시킨다면 아무리 큰 차원의 데이터라도 공간상에 분포시켜 가시화할 수 있게 됩니다. 바로 이런 경우에 활용할 수 있는 매우 강력한 기술이 t-SNE입니다. SNE는 Stochastic Neighbor Embedding의 약자이고 t는 정규분포와 유사한 그래프를 나타냅니다. 아래는 t 분포의 한 예에 대한 이미지입니다.

이 t-SNE를 이용하여 GAN이나 AutoEncoder 등에서 얻어지는 잠재벡터 z를 2차원 공간상에 분포시켜보는 내용을 구체적으로 살펴보겠습니다. Python의 Scikit-Learn 라이브러리에서 제공하는 t-SNE API를 이용하고, 잠재벡터 z는 아래의 AutoEncoder 포스팅에서 소개한 신경망에서 생성된 잠재벡터 값을 이용하겠습니다.
이 글에서 제시하는 최종 결과를 얻기 위해서는 위의 글을 통해 먼저 코드를 전제로 합니다. 먼저 위의 글의 소스코드에서 작성한 AutoEncdoer 신경망을 학습 한 이후에 다음의 코드를 통해 잠재 벡터 z를 얻어올 수 있습니다.
inp = transform(test_data.data.numpy().reshape(-1,28,28)) inp = inp.transpose(0,1) inp = inp.reshape(-1,1,28,28).to(device) z = model.encoder(inp) z = z.detach().cpu().numpy() y = test_data.targets.numpy()
AutoEncoder를 이해하고 있는 사람이라면 잠재벡터 z는 Encoder가 생성한 데이터라는 것을 알고 있을 것입니다. 이제 이렇게 생성한 z를 2차원 공간상에 시각화하는 위한 t-SNE 학습은 다음 코드와 같습니다.
from sklearn.manifold import TSNE import numpy as np tsne = TSNE(n_components=2, verbose=1, n_iter=300, perplexity=5) tsne_v = tsne.fit_transform(z[:6000])
데이터의 양이 너무 많으면 학습 시간이 많이 소요되므로 일단 6000개만 이용해 학습하였습니다. 학습이 완료되면 z를 2차원 상에 각 z에 해당되는 원래 이미지와 함께 공간상에 시각해 보면 다음과 같습니다.
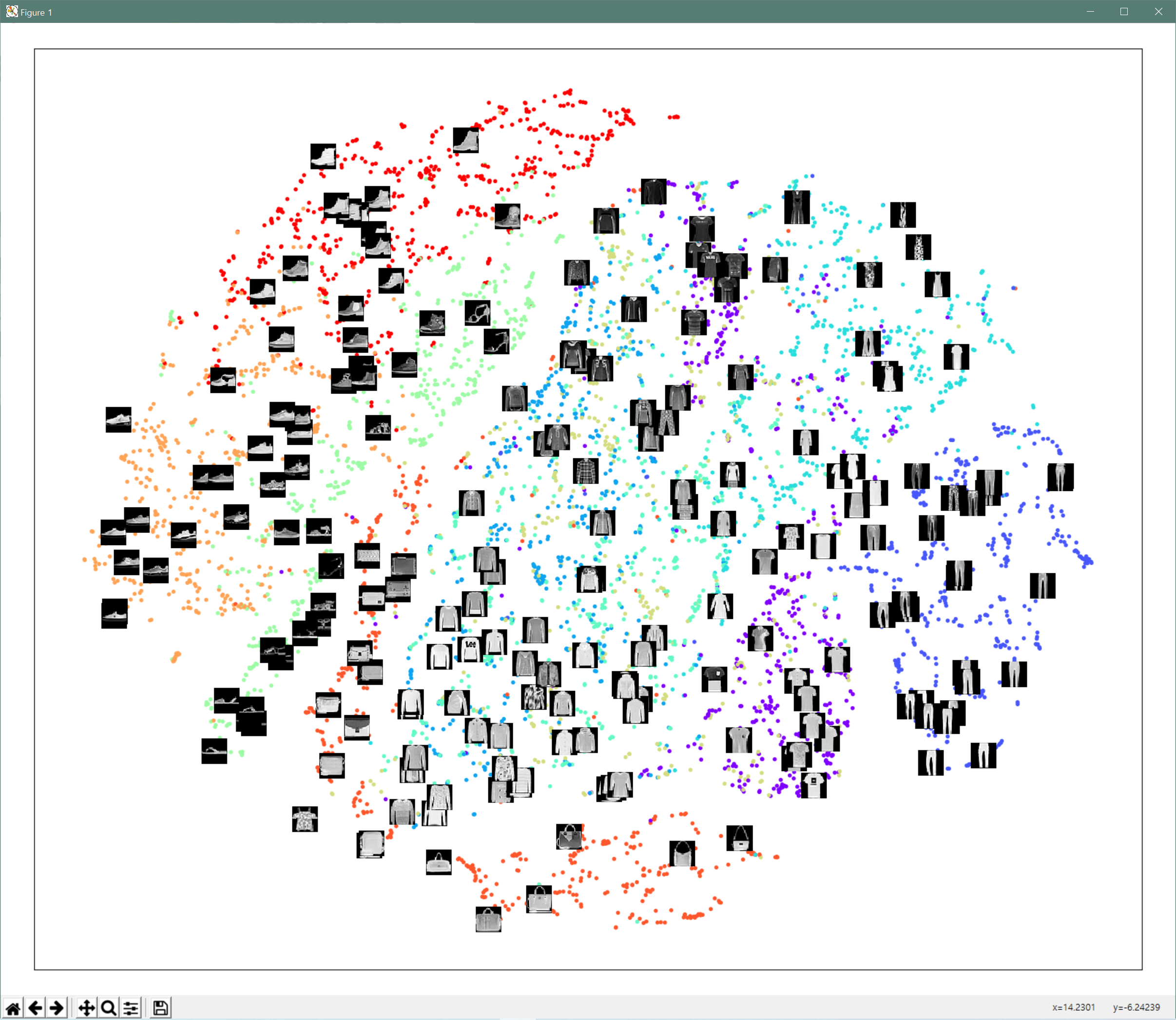
결과를 보면, 신발은 신발끼리 바지는 바지끼리.. 윗옷은 윗옷끼리 서로 그룹핑되어 분포하고 있는 것을 볼 수 있습니다. 좀더 세밀하게 관찰해보면 같은 신발이라도 신발의 세부 분류 항목으로 다시 그룹핑된다는 것입니다. 이는 AutoEncoder의 Encoder가 생성한 잠재벡터의 품질에 따라 그 성과가 달라질 것이고, 이러한 잠재벡터의 공간상 분포 가시화는 t-SNE를 통해 시각화가 가능하다라는 것입니다.