패턴명칭
Interpreter
필요한 상황
프로그램의 실행 상황을 제어할 수 있는 스크립트 언어를 지원할 수 있는 패턴이다.
예제 코드
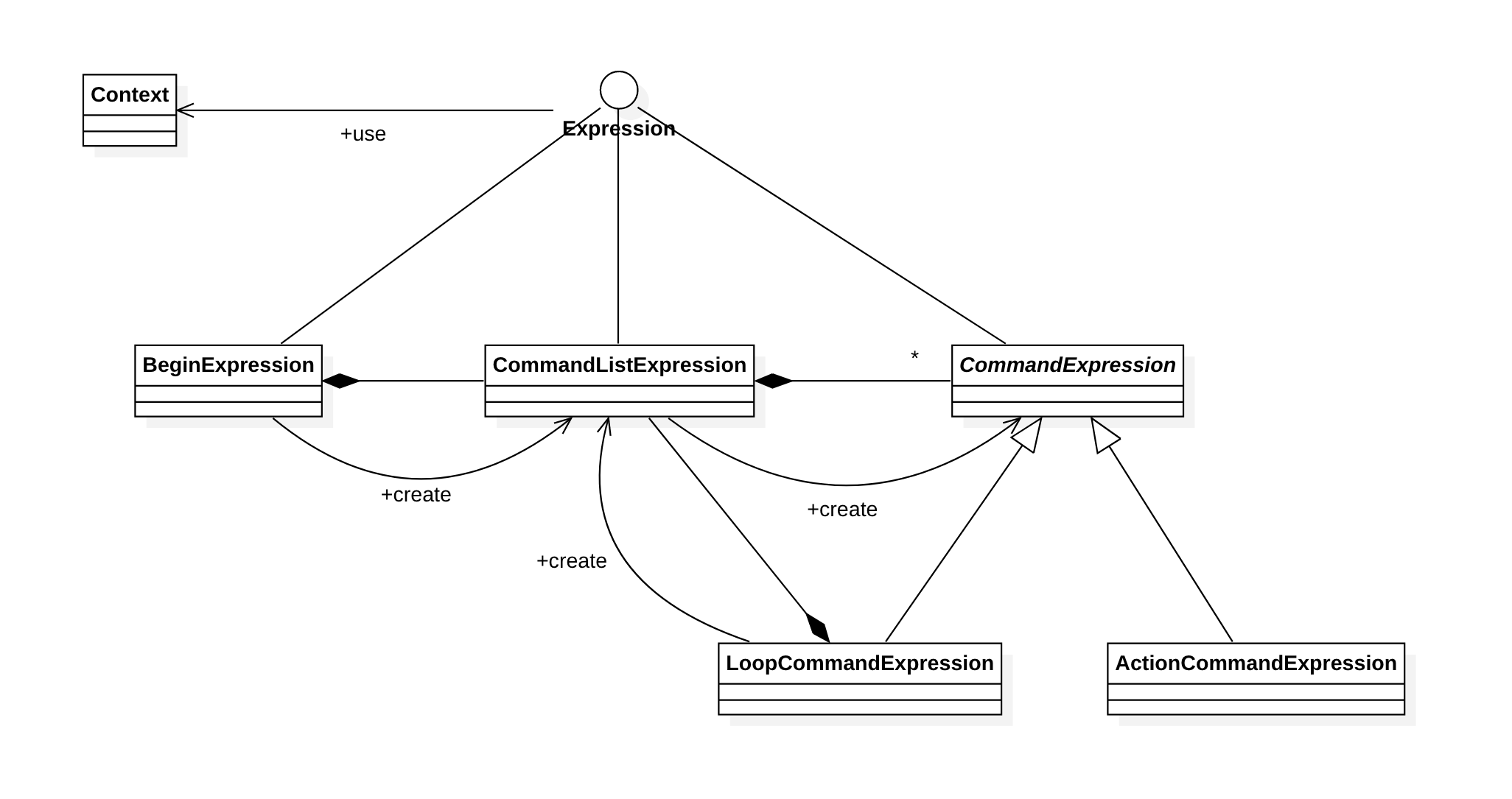
어떤 객체를 상(Front), 하(Back), 좌(Left), 우(Right)로 이동시키는 명령어로써 각각 FRONT, BACK, LEFT, RIGHT를 사용하고 이러한 명령어들의 조합을 반복할 수 있는 LOOP 명령어를 사용할 수 있는 스크립트 언어를 해석하기 위한 예제이다. Context는 스크립트에 대한 문자열을 받아 처리하는 클래스이고, Expression은 명령어들의 해석하고 처리하기 위한 클래스들이 구현해야 하는 인터페이스이다. 먼저 Context 클래스는 다음과 같다.
package tstThread;
import java.util.StringTokenizer;
public class Context {
private StringTokenizer tokenizer;
private String currentKeyword;
public Context(String script) {
tokenizer = new StringTokenizer(script);
readNextKeyword();
}
public String readNextKeyword() {
if(tokenizer.hasMoreTokens()) {
currentKeyword = tokenizer.nextToken();
} else {
currentKeyword = null;
}
return currentKeyword;
}
public String getCurrentKeyword() {
return currentKeyword;
}
}
Expression 인터페이스는 다음과 같다.
package tstThread;
public interface Expression {
boolean parse(Context context);
boolean run();
}
parse 매서드는 스크립트를 해석하고, run은 해석된 스크립트를 실제로 실행하는 매서드이다. 스크립트의 예제로 다음 문자열을 사용한다.
BEGIN FRONT LOOP 3 LOOP 2 RIGHT FRONT END LOOP 3 LEFT END BACK RIGHT END BACK END
스크립트는 BEGIN으로 시작해서 END로 끝나며, 반복문인 LOOP는 반복 회수로 시작해서 반복할 명령어들로 구성되고 END로 끝난다.
Expression 인터페이스를 구현하는 클래스들을 살펴보자. 먼저 스크립트의 시작을 해석하는 BeginExpression이다.
package tstThread;
public class BeginExpression implements Expression {
private CommandListExpression expression;
@Override
public boolean parse(Context context) {
if(checkValidKeyword(context.getCurrentKeyword())) {
context.readNextKeyword();
expression = new CommandListExpression();
return expression.parse(context);
} else {
return false;
}
}
public String toString() {
return "BEGIN " + expression;
}
@Override
public boolean run() {
return expression.run();
}
public static boolean checkValidKeyword(String keyword) {
return keyword.equals("BEGIN");
}
}
다음은 CommandListExpression 이다.
package tstThread;
import java.util.ArrayList;
import java.util.Iterator;
public class CommandListExpression implements Expression {
private ArrayList<CommandExpression> commands = new ArrayList<CommandExpression>();
@Override
public boolean parse(Context context) {
while(true) {
String currentKeyword = context.getCurrentKeyword();
if(currentKeyword == null) {
return false;
} else if(currentKeyword.equals("END")) {
context.readNextKeyword();
break;
} else {
CommandExpression command = null;
if(LoopCommandExpression.checkValidKeyword(currentKeyword)) {
command = new LoopCommandExpression(currentKeyword);
} else if(ActionCommandExpression.checkValidKeyword(currentKeyword)) {
command = new ActionCommandExpression(currentKeyword);
}
if(command != null) {
if(command.parse(context)) {
commands.add(command);
} else {
return false;
}
} else {
return false;
}
}
}
return true;
}
public String toString() {
return commands.toString();
}
@Override
public boolean run() {
Iterator<CommandExpression> iter = commands.iterator();
while(iter.hasNext()) {
boolean bOK = iter.next().run();
if(!bOK) return false;
}
return true;
}
}
CommandListExpression은 실제 실행이 가능한 LOOP나 FRONT, BACK, RIGHT, LEFT 명령어를 담을 담을 수 있는 CommandExpression의 파생클래스를 생성해 주는 책임을 진다. CommandExpression의 클래스는 다음과 같다.
package tstThread;
public abstract class CommandExpression implements Expression {
protected String keyword;
public CommandExpression(String keyword) {
this.keyword = keyword;
}
}
CommandExpression 추상 클래스를 상속받는 클래스들을 살펴보자. 먼저 LoopCommandExpression 클래스이다.
package tstThread;
public class LoopCommandExpression extends CommandExpression {
private int count;
private CommandListExpression expression;
public LoopCommandExpression(String keyword) {
super(keyword);
}
@Override
public boolean parse(Context context) {
if(!checkValidKeyword(keyword)) return false;
String countKeyword = context.readNextKeyword();
if(countKeyword == null) return false;
try {
count = Integer.parseInt(countKeyword);
expression = new CommandListExpression();
if(context.readNextKeyword() == null) return false;
return expression.parse(context);
} catch(NumberFormatException e) {
return false;
}
}
public String toString() {
return "LOOP(" + count + ") " + expression;
}
@Override
public boolean run() {
for(int i=0; i<count; i++) {
if(!expression.run()) {
return false;
}
}
return true;
}
public static boolean checkValidKeyword(String keyword) {
return keyword.equals("LOOP");
}
}
다음은 ActionCommandExpression 클래스이다.
package tstThread;
public class ActionCommandExpression extends CommandExpression {
public ActionCommandExpression(String keyword) {
super(keyword);
}
@Override
public boolean parse(Context context) {
if(!checkValidKeyword(keyword)) return false;
if(context.readNextKeyword() == null) return false;
return true;
}
public String toString() {
return keyword;
}
@Override
public boolean run() {
System.out.println("cmd: " + keyword);
return true;
}
public static boolean checkValidKeyword(String keyword) {
boolean bKeywordOk = keyword.equals("FRONT") ||
keyword.equals("BACK") || keyword.equals("LEFT") ||
keyword.equals("RIGHT");
return bKeywordOk;
}
}
지금까지의 클래스들을 사용하는 예제는 다음과 같다.
package tstThread;
public class Main {
public static void main(String[] args) {
//String script = "BEGIN FRONT LOOP 2 RIGHT FRONT LEFT LEFT BACK RIGHT END BACK END";
//String script = "BEGIN FRONT LOOP 2 RIGHT FRONT LOOP 3 LEFT LEFT END BACK RIGHT END BACK END";
String script = "BEGIN FRONT LOOP 3 LOOP 2 RIGHT FRONT END LOOP 3 LEFT END BACK RIGHT END BACK END";
Context context = new Context(script);
Expression expression = new BeginExpression();
System.out.println(script);
if(expression.parse(context)) {
System.out.println(expression);
expression.run();
} else {
System.out.println("Parsing error");
}
}
}
실행 결과는 다음과 같다.
BEGIN FRONT LOOP 3 LOOP 2 RIGHT FRONT END LOOP 3 LEFT END BACK RIGHT END BACK END
BEGIN [FRONT, LOOP(3) [LOOP(2) [RIGHT, FRONT], LOOP(3) [LEFT], BACK, RIGHT], BACK]
cmd: FRONT
cmd: RIGHT
cmd: FRONT
cmd: RIGHT
cmd: FRONT
cmd: LEFT
cmd: LEFT
cmd: LEFT
cmd: BACK
cmd: RIGHT
cmd: RIGHT
cmd: FRONT
cmd: RIGHT
cmd: FRONT
cmd: LEFT
cmd: LEFT
cmd: LEFT
cmd: BACK
cmd: RIGHT
cmd: RIGHT
cmd: FRONT
cmd: RIGHT
cmd: FRONT
cmd: LEFT
cmd: LEFT
cmd: LEFT
cmd: BACK
cmd: RIGHT
cmd: BACK