
GAN은 Generative Adversarial Network로 적대적 생성 신경망입니다. 즉, 무언가를 생성하는 신경망인데.. 그 무언가를 제대로 잘생성하기 위해 누군가를 잘속이기 위한 전략을 취합니다. 흔히 GAN에 대한 이러한 설명을 위조지폐범과 지폐판별사의 예를 많이 듭니다. 위조지폐범은 위조지폐를 만들어 지폐판별사에게 전달하면 판별사는 이게 가짜인지 진짜인지를 판별해서 지폐범에게 얼마나 가짜같은지를 알려주고, 위조지폐범은 판별사에게서 얻은 피드백을 통해 좀더 진짜같은 위조지폐를 만들어 다시 판별사에게 전달합니다. 이러한 과정을 반복하다보면 위조지폐범은 더욱 진짜 같은 위조지폐를 만들 수 있게 된다는 것입니다. 이러한 설명을 도식으로 표현해 보면 다음과 같습니다.
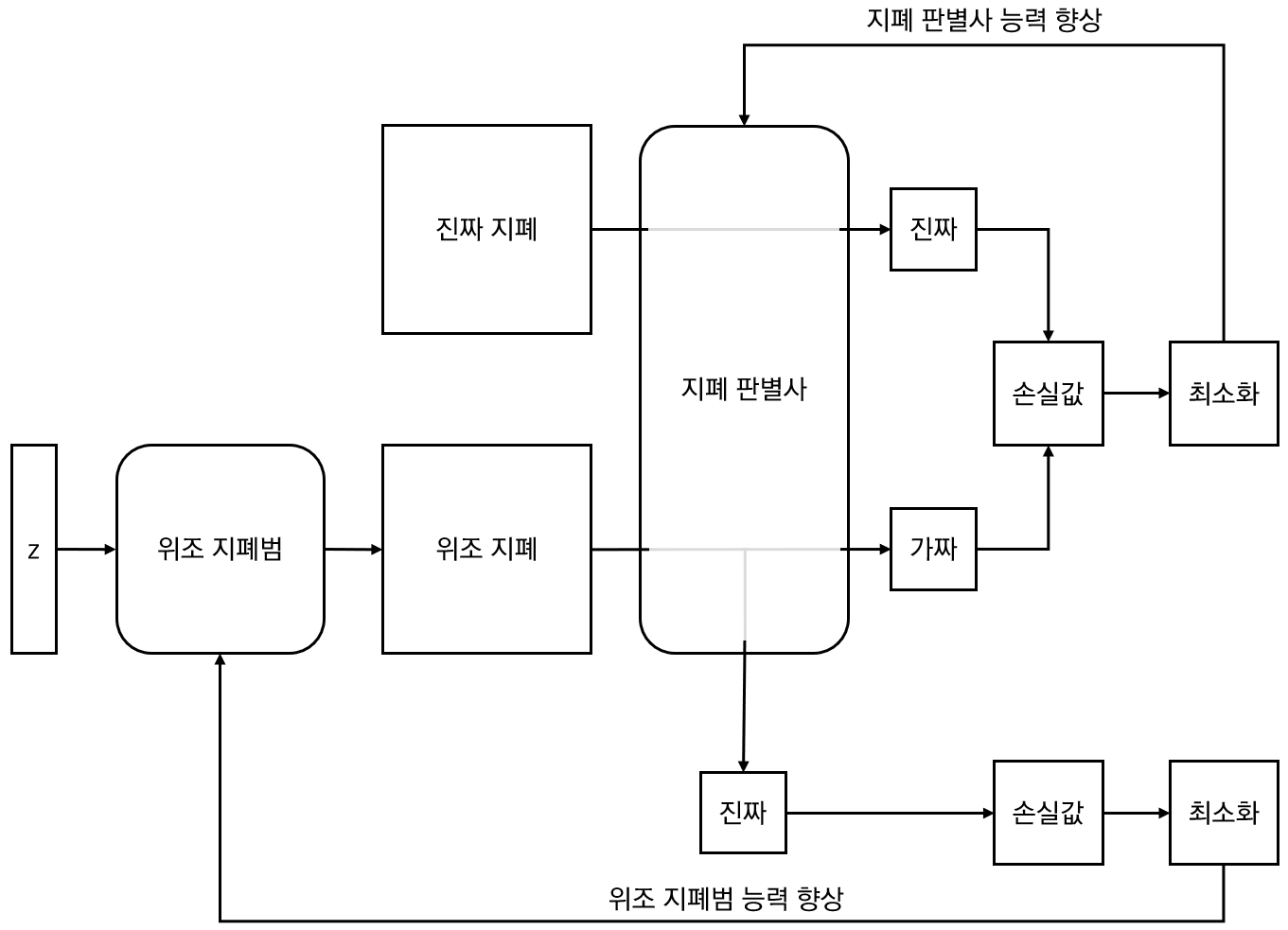
위의 그림에서 위조 지폐범과 지폐 판별사는 각각 신경망 모델입니다. 이 두 신경망 모델 학습을 위해 학습시 얻어지는 손실값 최소화를 통해 신경망의 능력을 향상시켜나가게 됩니다. GAN은 위조지폐처럼 이미지를 생성하는 것뿐만 아니라 입력 데이터에 따라 텍스트나 작곡 등도 가능합니다. 또한 GAN은 레이블 데이터가 필요없는 비지도학습에 속합니다. 즉, GAN을 통해 생성하고자 하는 종류의 데이터만 있으면 됩니다. 초기의 GAN은 단순한 Linear Layer(선형 레이어)만으로 구성할 수 있습니다. 그러나 생성하고자 하는 데이터에 따라… 즉 이미지의 경우는 Convolutional Layer로 구성하는 것이 효과적입니다. 이 글에서는 이 두가지 경우 모두를 언급합니다.
먼저 선형 레이어만으로 구성된 GAN에 대한 실제 구현입니다.
딥러닝을 위한 라이브러리로 PyTorch를 사용하므로 다음처럼 필요한 라이브러리 등을 불러옵니다.
import os import torch import torch.nn as nn import torchvision import torch.optim as optim from torchvision import transforms, datasets import matplotlib.pyplot as plt import numpy as np
다음으로 반복 학습수와 배치수, 그리고 GPU를 지원하는지의 여부에 따른 준비를 다음 코드를 통해 지정합니다.
EPOCHS = 1000
BATCH_SIZE = 128
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
우리가 생성할 이미지 데이터는 MNIST의 숫자 데이터입니다. 보다 복잡한 이미지도 가능하지만, 여기서는 빠른 학습과 분명한 결과 확인을 위해 MNSIT 숫자 데이터를 사용했습니다.
trainset = datasets.MNIST("./data", train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
)
train_loader = torch.utils.data.DataLoader(dataset = trainset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
앞서 그림을 보면 위조지폐범에 z 값이 입력되고 있는 것을 볼 수 있습니다. 이 z는 잠재 벡터(Latent Vector)인데요. 이 잠재 벡터의 구성 값에 따라 어떤 이미지가 생성되는지 결정됩니다. 이 잠재 벡터를 구성하는 값의 개수를 아래 코드로 정의합니다.
z_size = 72
이제 이미지를 생성하는 신경망 모델을 정의합니다.
class GNet(nn.Module):
def __init__(self):
super().__init__()
self._layers = nn.Sequential(
nn.Linear(z_size, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 784),
nn.Tanh()
)
def forward(self, x):
return self._layers(x)
잠재 벡터의 크기값만큼 입력받아 최종적으로 이미지의 크기인 784(이미지 크기: 28×28)로 출력합니다. 원활한 학습을 위해 활성화함수로 ReLU를 사용했고, 마지막 활성화함수는 Tanh를 사용했는데.. 이는 이미지를 구성하는 값들의 범위가 -1~1이고, 이를 맞춰주기 위해 Tanh를 사용한 것입니다.
다음은 이미지의 진짜와 가짜를 판별하는 신경망 모델입니다.
class DNet(nn.Module):
def __init__(self):
super().__init__()
self._layers = nn.Sequential(
nn.Linear(784, 512),
nn.LeakyReLU(0.25),
nn.Linear(512, 256),
nn.LeakyReLU(0.25),
nn.Linear(256, 128),
nn.LeakyReLU(0.25),
nn.Linear(128,1),
nn.Sigmoid()
)
def forward(self, x):
return self._layers(x)
이제 두개의 신경망을 학습하기 위해 두 신경망을 생성하고, 손실값 계산을 위해 Binary Cross Entropy Loss인 BCELoss를 사용합니다. 또한 손실값에 대한 경사하강을 통해 가중치들의 최적화를 위한 Adam을 사용합니다. 생성자와 판별자 각각을 학습해야 하므로 최적화를 위한 객체는 각각을 위해 2개가 필요합니다. 그리고 이미지가 진짜인지, 가짜인지에 대한 레이블 데이터를 생성해 둡니다.
D = DNet().to(DEVICE) G = GNet().to(DEVICE) criterion = nn.BCELoss() d_optimizer = optim.Adam(D.parameters(), lr=0.0002) g_optimizer = optim.Adam(G.parameters(), lr=0.0002) real_labels = torch.ones(BATCH_SIZE, 1).to(DEVICE) fake_labels = torch.zeros(BATCH_SIZE, 1).to(DEVICE)
이제 실제 신경망의 학습 코드입니다.
fig, axes = plt.subplots(4,3)
for epoch in range(EPOCHS):
for i, (images, _) in enumerate(train_loader):
images = images.reshape(BATCH_SIZE, -1).to(DEVICE)
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
z = torch.randn(BATCH_SIZE, z_size).to(DEVICE)
fake_images = G(z)
outputs = D(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
print('Epoch[{:3d}/{:3d}] d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'.format(
epoch, EPOCHS, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
z = torch.randn(BATCH_SIZE, z_size).to(DEVICE)
fake_images = G(z)
for row in range(4):
for col in range(3):
fake_images_img = np.reshape(fake_images.data.cpu().numpy()[row*4+col],(28,28))
axis = axes[row][col]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(fake_images_img, cmap='gray')
plt.savefig('./data/DNN_GAN_{:03d}.jpg'.format(epoch))
매 학습 단계마다 학습된 신경망으로 12개의 이미지를 생성해 저장하도록 하였습니다. 각 학습 단계에서는 먼저 진짜 이미지와 가짜 이미지를 판별자에게 판별하도록 하고 판별시 얻어지는 손실값을 합하여 역전파하여 최소화으로써 판별자를 학습시킵니다. 그리고 판별자를 통해 가짜 이미지를 진짜 이미지라고 판별하라고 했을때 발생하는 손실값을 역전파하여 최소화함으로써 생성자를 학습시킵니다.
GAN은 많은 학습이 필요하므로 상당한 시간이 소요됩니다. 아래는 각 에폭 단위별 순서대로 생성된 결과입니다.

선형 레이어만으로 GAN을 구현하면 학습이 더디게 걸린다는 문제와 높은 품질의 결과와 좀더 다양한 이미지들이 생성되지 않는다는 문제가 있습니다. 이를 해결하기 위해서는 이미지 생성을 위한 GAN에 Convolutional Layer를 적용한 DCGAN(Deep Convolutional GAN)에 대해 설펴 보겠습니다.
DCGAN과 GAN의 차이점은 신경망의 구성뿐입니다. 물론 신경망이 변경되므로 입력되는 데이터, 즉 텐서들의 차원이 변경되는 부분 역시 신경을 써줘야 합니다. DCGAN의 신경망 코드와 신경망에 입력되는 텐서들의 차원 변경에 따른 코드는 신경망 학습 코드에서 나타나므로 신경망 학습 부분에 대한 코드만을 살펴 보겠습니다. 먼저 DCGAN의 생성자와 판별자에 대한 신경망 코드입니다.
class GNet(nn.Module):
def __init__(self):
super().__init__()
self._layers = nn.Sequential(
nn.ConvTranspose2d(z_size, 32, 3, 1, 0, bias=False), # 1 -> 3
nn.BatchNorm2d(32),
nn.ReLU(inplace=False),
nn.ConvTranspose2d(32, 16, 4, 2, 1, bias=False), # 3 -> 6
nn.BatchNorm2d(16),
nn.ReLU(inplace=False),
nn.ConvTranspose2d(16, 8, 4, 2, 0, bias=False), # 6 -> 14
nn.BatchNorm2d(8),
nn.ReLU(inplace=False),
nn.ConvTranspose2d(8, 1, 4, 2, 1, bias=False), # 14 -> 28
nn.Tanh()
)
def forward(self, x):
return self._layers(x)
class DNet(nn.Module):
def __init__(self):
super().__init__()
self._layers = nn.Sequential(
nn.Conv2d(1, 8, 4, 2, 1, bias=False), # 28 -> 14
nn.BatchNorm2d(8),
nn.LeakyReLU(0.2, inplace=False),
nn.Conv2d(8, 16, 4, 2, 1, bias=False), # 14 -> 7
nn.BatchNorm2d(16),
nn.LeakyReLU(0.2, inplace=False),
nn.Conv2d(16, 32, 4, 2, 1, bias=False), # 7 -> 3
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=False),
nn.Conv2d(32, 1, 4, 2, 1, bias=False), # 3 -> 1
nn.Sigmoid(),
)
def forward(self, x):
return self._layers(x).squeeze()
Convolution Layer로써 생성자에서는 ConvTranspose2d를 사용하여 잠재 벡터(z)로 시작해 이미지를 점차 키워나가며 생성하고, 판별자에서는 Conv2d를 사용하여 이미지의 특성을 추출하다가 마지막에 Sigmoid 함수를 통해 0~1사이의 값을 뽑아냅니다. 이 값이 바로 이미지가 가짜(0)인지 진짜(1)인지에 대한 판별 여부입니다. Convolutional Layer는 이미지를 대상으로 하므로 입력 이미지의 크기와 마지막 출력 이미지의 크기를 원하는 크기에 맞추기 위해 Filter와 Stride, Padding 등의 값을 조정해줘야 합니다. 아래는 이럴때 사용할 수 있는 수식입니다.
먼저 nn.ConvTranspose2d 연산을 통해 입력 이미지의 크기가 어떤 크기의 출력 이미지로 변경되는지에 대한 수식입니다.

다음은 nn.Conv2d 연산을 통해 입력 이미지의 크기가 어떤 크기의 출력 이미지로 변경되는지에 대한 수식입니다. 결과의 소수점은 버립니다.

그리고 다음은 학습 코드입니다. 앞서 언급한 것처럼 코드 구성은 GAN과 동일하고 입력 데이터의 차원 크기에 의한 미세한 변화가 있을뿐입니다.
fig, axes = plt.subplots(4,3)
for epoch in range(EPOCHS):
for i, (images, _) in enumerate(train_loader):
images = images.to(DEVICE)
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
z = torch.randn(BATCH_SIZE, z_size, 1, 1).to(DEVICE)
fake_images = G(z)
outputs = D(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
print('Epoch[{:3d}/{:3d}] d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'.format(
epoch, EPOCHS, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
z = torch.randn(BATCH_SIZE, z_size, 1, 1).to(DEVICE)
fake_images = G(z)
for row in range(4):
for col in range(3):
fake_images_img = np.reshape(fake_images.data.cpu().numpy()[row*4+col],(28,28))
axis = axes[row][col]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(fake_images_img, cmap='gray')
plt.savefig('./data/CNN_GAN_{:03d}.jpg'.format(epoch))
실행해보면 GAN보다 DCGAN이 더 빨리 의미있는 이미지를 생성해 내기 시작합니다. 또한 보다 더 높은 품질의, 더 다양한 이미지를 생성해 보내는 것을 확인할 수 있습니다. 아래는 DCGAN에 의한 각 에폭 단위별 순서대로 생성된 결과입니다.


![$$loss(x,class)=-\log\biggl(\frac{\exp(x[class])}{\sum_{j}{\exp(x[j])}}\biggr)=-x[class]+\log\biggl(\sum_{j}{\exp(x[j])}}\biggr)$$](http://www.gisdeveloper.co.kr/wp-content/ql-cache/quicklatex.com-f3208d5dfaaecd0f28069ec368ceb1f7_l3.png "Rendered by QuickLaTeX.com")