
아래와 같은 식을 회귀하는 모델을 구하는 두가지 접근을 PyTorch로 살펴본다.

즉, 입력값(a, b)에 대한 출력값 y가 100개 주어지고, 이 데이터를 통해 상수항인 1과 계수 5, 7을 구하는 것이 문제다. 물론 y에는 오차가 반영되어 있다. 첫번째 접근은 다음과 같다. 손실함수는 평균최소제곱을, 역전파를 통한 최적값 수렴을 위한 기울기를 구해 반영한 학습률은 0.01을 사용했다. 아래의 코드의 경우 기울기를 구하기 위한 방법을 PyTorch의 역전파를 이용한 것이다.
import torch
from matplotlib import pyplot as plt
weight_true = torch.Tensor([1,5,7]) # y = 1 + 5a + 7b
X = torch.cat([torch.ones(100,1),torch.randn(100,2)], 1)
y = torch.mv(X, weight_true) + torch.randn(100)
weight = torch.randn(3, requires_grad=True)
lr = 0.01
losses = []
for epoch in range(1000):
weight.grad = None
y_pred = torch.mv(X, weight)
loss = torch.mean((y - y_pred)**2)
loss.backward()
weight.data = weight.data - lr*weight.grad.data
losses.append(loss.item())
print(weight)
plt.plot(losses)
plt.show()
두번째 접근은 다음과 같다. 앞서 직접 하나 하나 개발자가 지정했던 것들에 대한 모듈을 사용한 경우이다.
import torch
from torch import nn, optim
from matplotlib import pyplot as plt
weight_true = torch.Tensor([1,5,7]) # y = 1 + 5a + 7b
X = torch.cat([torch.ones(100,1),torch.randn(100,2)], 1)
y = torch.mv(X, weight_true) + torch.randn(100)
net = nn.Linear(in_features=3, out_features=1, bias=False)
optimizer = optim.SGD(net.parameters(), lr=0.01)
loss_fn = nn.MSELoss()
losses = []
for epoch in range(1000):
optimizer.zero_grad()
y_pred = net(X)
loss = loss_fn(y_pred.view_as(y), y)
loss.backward()
optimizer.step()
losses.append(loss.item())
print(net.weight)
plt.plot(losses)
plt.show()
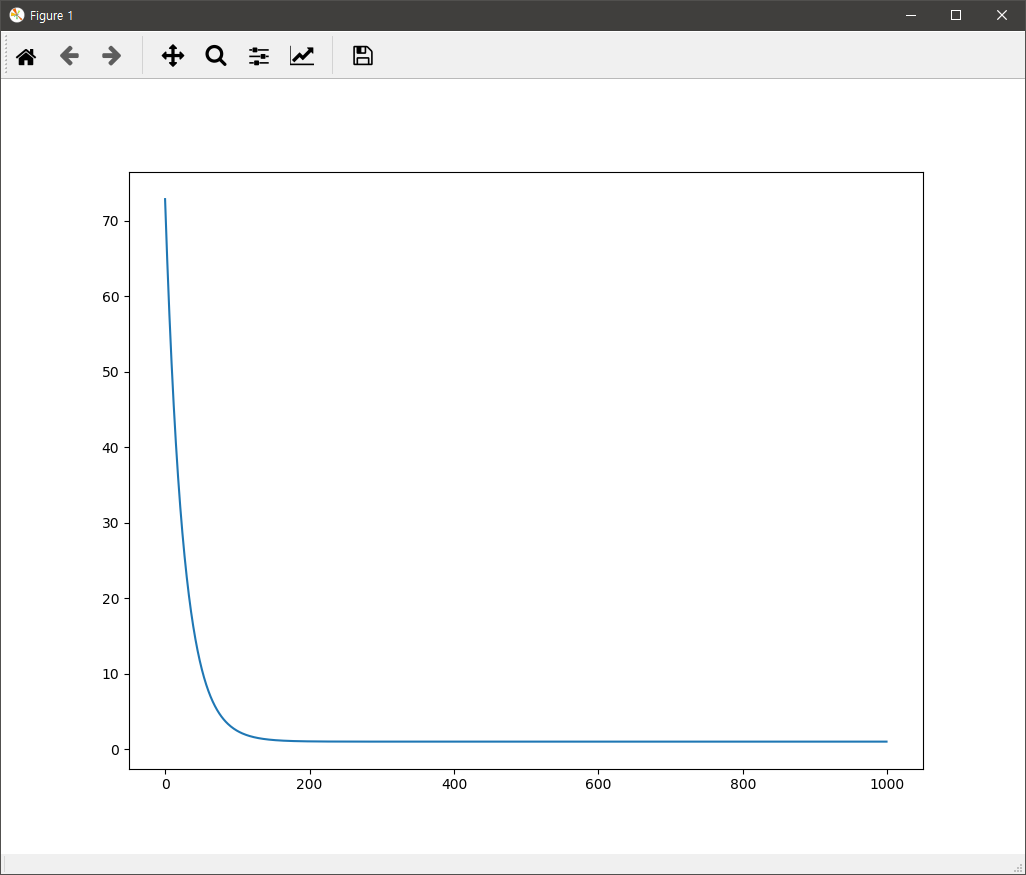
두 경우 모두 실행하면 아래와 같은 손실값에 대한 그래프와 추론된 상수와 두계수 값이 콘솔에 출력된다.
tensor([0.9295, 4.9402, 7.0627], requires_grad=True)