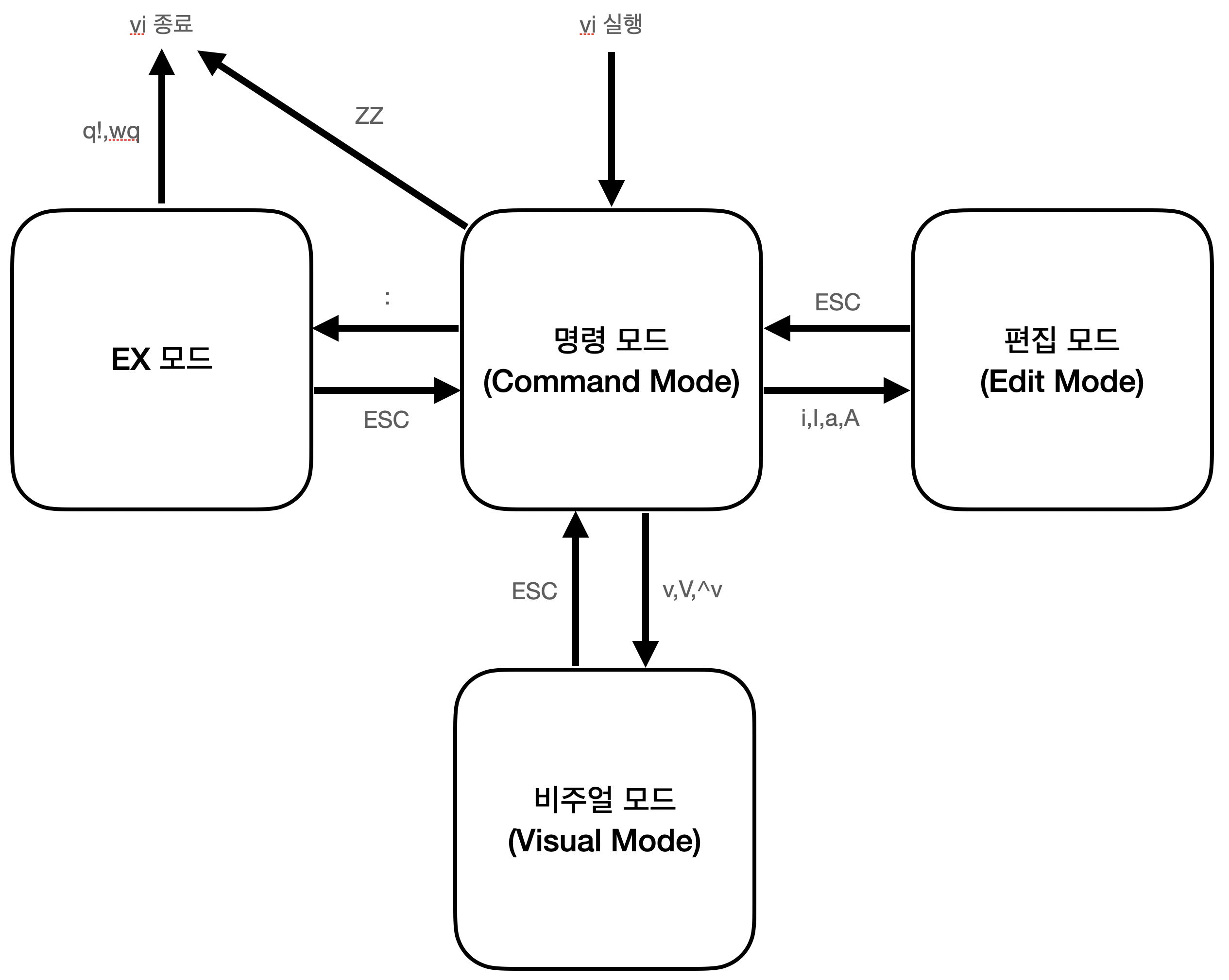
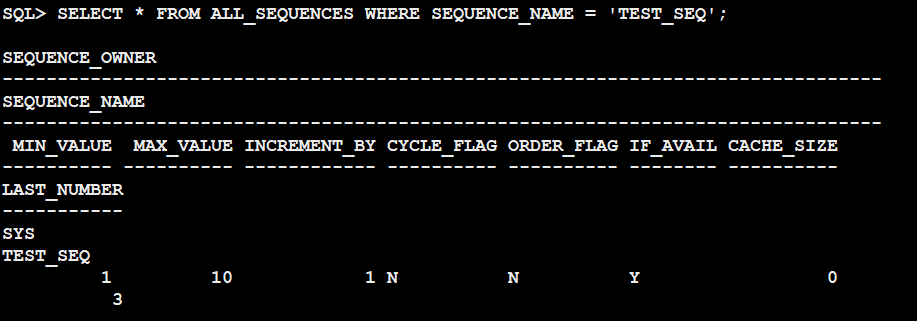
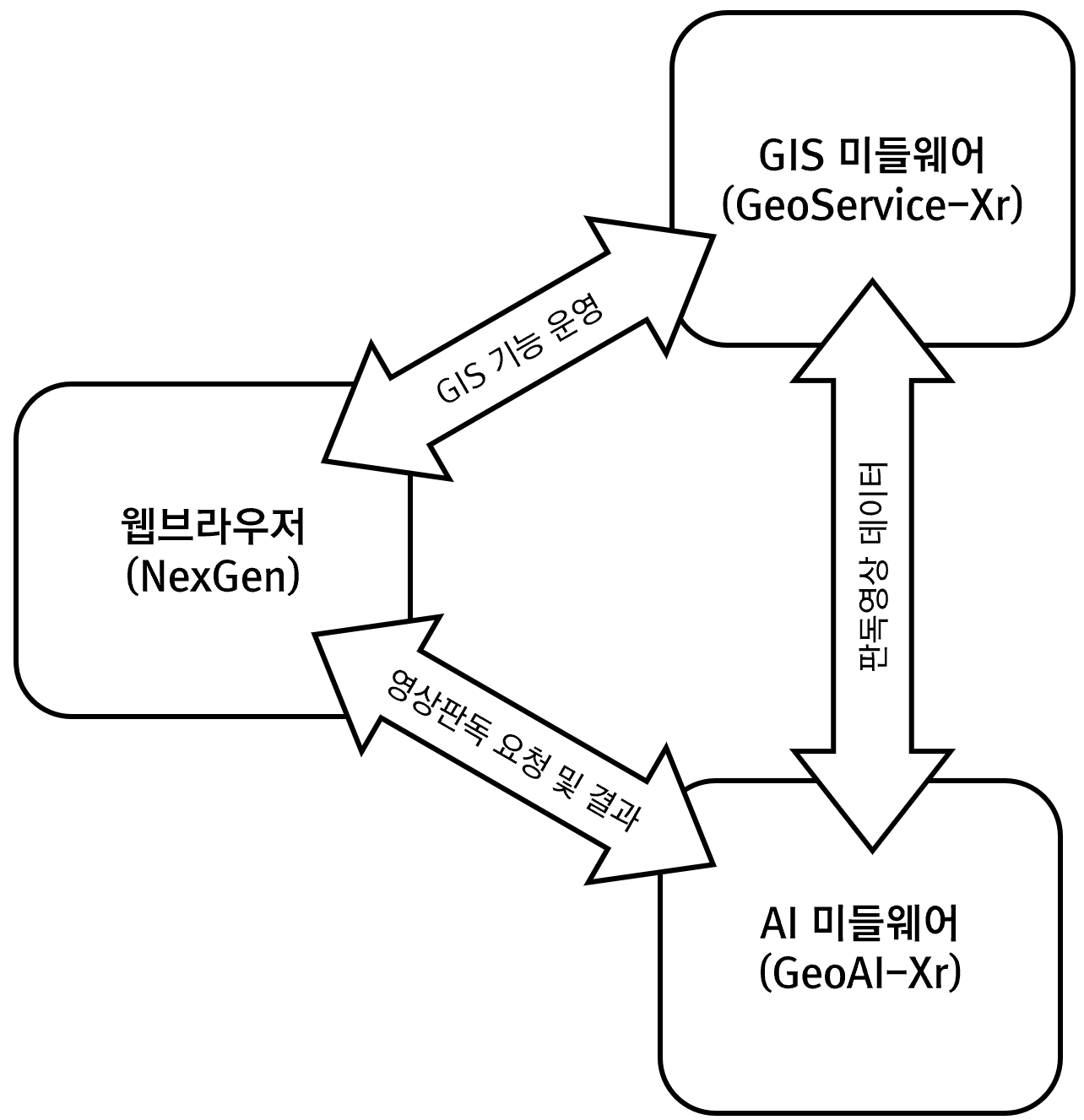
지리정보시스템(GIS)의 원시 데이터 중 CAD에 대한 시각화를 위한 색상 테이블을 정리한 표입니다.
0 (#000000)
1 (#FF0000)
2 (#FFFF00)
3 (#00FF00)
4 (#00FFFF)
5 (#0000FF)
6 (#FF00FF)
7 (#FFFFFF)
8 (#414141)
9 (#808080)
10 (#FF0000)
11 (#FFAAAA)
12 (#BD0000)
13 (#BD7E7E)
14 (#810000)
15 (#815656)
16 (#680000)
17 (#684545)
18 (#4F0000)
19 (#4F3535)
20 (#FF3F00)
21 (#FFBFAA)
22 (#BD2E00)
23 (#BD8D7E)
24 (#811F00)
25 (#816056)
26 (#681900)
27 (#684E45)
28 (#4F1300)
29 (#4F3B35)
30 (#FF7F00)
31 (#FFD4AA)
32 (#BD5E00)
33 (#BD9D7E)
34 (#814000)
35 (#816B56)
36 (#683400)
37 (#685645)
38 (#4F2700)
39 (#4F4235)
40 (#FFBF00)
41 (#FFEAAA)
42 (#BD8D00)
43 (#BDAD7E)
44 (#816000)
45 (#817656)
46 (#684E00)
47 (#685F45)
48 (#4F3B00)
49 (#4F4935)
50 (#FFFF00)
51 (#FFFFAA)
52 (#BDBD00)
53 (#BDBD7E)
54 (#818100)
55 (#818156)
56 (#686800)
57 (#686845)
58 (#4F4F00)
59 (#4F4F35)
60 (#BFFF00)
61 (#EAFFAA)
62 (#8DBD00)
63 (#ADBD7E)
64 (#608100)
65 (#768156)
66 (#4E6800)
67 (#5F6845)
68 (#3B4F00)
69 (#494F35)
70 (#7FFF00)
71 (#D4FFAA)
72 (#5EBD00)
73 (#9DBD7E)
74 (#408100)
75 (#6B8156)
76 (#346800)
77 (#566845)
78 (#274F00)
79 (#424F35)
80 (#3FFF00)
81 (#BFFFAA)
82 (#2EBD00)
83 (#8DBD7E)
84 (#1F8100)
85 (#608156)
86 (#196800)
87 (#4E6845)
88 (#134F00)
89 (#3B4F35)
90 (#00FF00)
91 (#AAFFAA)
92 (#00BD00)
93 (#7EBD7E)
94 (#008100)
95 (#568156)
96 (#006800)
97 (#456845)
98 (#004F00)
99 (#354F35)
100 (#00FF3F)
101 (#AAFFBF)
102 (#00BD2E)
103 (#7EBD8D)
104 (#00811F)
105 (#568160)
106 (#006819)
107 (#45684E)
108 (#004F13)
109 (#354F3B)
110 (#00FF7F)
111 (#AAFFD4)
112 (#00BD5E)
113 (#7EBD9D)
114 (#008140)
115 (#56816B)
116 (#006834)
117 (#456856)
118 (#004F27)
119 (#354F42)
120 (#00FFBF)
121 (#AAFFEA)
122 (#00BD8D)
123 (#7EBDAD)
124 (#008160)
125 (#568176)
126 (#00684E)
127 (#45685F)
128 (#004F3B)
129 (#354F49)
130 (#00FFFF)
131 (#AAFFFF)
132 (#00BDBD)
133 (#7EBDBD)
134 (#008181)
135 (#568181)
136 (#006868)
137 (#456868)
138 (#004F4F)
139 (#354F4F)
140 (#00BFFF)
141 (#AAEAFF)
142 (#008DBD)
143 (#7EADBD)
144 (#006081)
145 (#567681)
146 (#004E68)
147 (#455F68)
148 (#003B4F)
149 (#35494F)
150 (#007FFF)
151 (#AAD4FF)
152 (#005EBD)
153 (#7E9DBD)
154 (#004081)
155 (#566B81)
156 (#003468)
157 (#455668)
158 (#00274F)
159 (#35424F)
160 (#003FFF)
161 (#AABFFF)
162 (#002EBD)
163 (#7E8DBD)
164 (#001F81)
165 (#566081)
166 (#001968)
167 (#454E68)
168 (#00134F)
169 (#353B4F)
170 (#0000FF)
171 (#AAAAFF)
172 (#0000BD)
173 (#7E7EBD)
174 (#000081)
175 (#565681)
176 (#000068)
177 (#454568)
178 (#00004F)
179 (#35354F)
180 (#3F00FF)
181 (#BFAAFF)
182 (#2E00BD)
183 (#8D7EBD)
184 (#1F0081)
185 (#605681)
186 (#190068)
187 (#4E4568)
188 (#13004F)
189 (#3B354F)
190 (#7F00FF)
191 (#D4AAFF)
192 (#5E00BD)
193 (#9D7EBD)
194 (#400081)
195 (#6B5681)
196 (#340068)
197 (#564568)
198 (#27004F)
199 (#42354F)
200 (#BF00FF)
201 (#EAAAFF)
202 (#8D00BD)
203 (#AD7EBD)
204 (#600081)
205 (#765681)
206 (#4E0068)
207 (#5F4568)
208 (#3B004F)
209 (#49354F)
210 (#FF00FF)
211 (#FFAAFF)
212 (#BD00BD)
213 (#BD7EBD)
214 (#810081)
215 (#815681)
216 (#680068)
217 (#684568)
218 (#4F004F)
219 (#4F354F)
220 (#FF00BF)
221 (#FFAAEA)
222 (#BD008D)
223 (#BD7EAD)
224 (#810060)
225 (#815676)
226 (#68004E)
227 (#68455F)
228 (#4F003B)
229 (#4F3549)
230 (#FF007F)
231 (#FFAAD4)
232 (#BD005E)
233 (#BD7E9D)
234 (#810040)
235 (#81566B)
236 (#680034)
237 (#684556)
238 (#4F0027)
239 (#4F3542)
240 (#FF003F)
241 (#FFAABF)
242 (#BD002E)
243 (#BD7E8D)
244 (#81001F)
245 (#815660)
246 (#680019)
247 (#68454E)
248 (#4F0013)
249 (#4F353B)
250 (#333333)
251 (#505050)
252 (#696969)
253 (#828282)
254 (#BEBEBE)
255 (#FFFFFF)