패턴명칭
Template
필요한 상황
처리에 대한 로직은 정해져 있을 때, 이 로직을 구성하는 각각의 세부 항목에 대한 처리들을 다르게 정의하고자할때 사용할 수 있는 패턴이다.
예제 코드
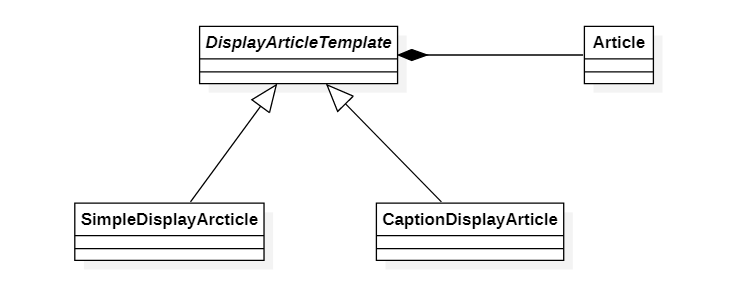
위의 클래스다이어그램에서 DisplayArticleTemplate은 이미 정해진 로직을 정의하는 클래스이며, 이 로직을 구성하는 항목들의 세부 처리에 대한 인터페이스만을 정의하고 있는 추상클래스이다. 이 클래스를 상속받아 각 세부 항목을 구현해야 하는데, SimpleDisplayArticle과 CaptionDisplayArticle이 바로 그 클래스이다. DisplayArticleTemplate 클래스는 어떤 데이터를 화면에 출력하는 일을 하는데, 출력하는 대상이 되는 데이터는 Article 클래스의 인스턴스에 저장된다.
먼저 Article 클래스는 다음과 같다.
package pattern;
import java.util.ArrayList;
public class Article {
private String title;
private ArrayList<String> content;
private String footer;
public Article(String title, ArrayList<String> content, String footer) {
this.title = title;
this.content = content;
this.footer = footer;
}
public String getTitle() {
return title;
}
public ArrayList<String> getContent() {
return content;
}
public String getFooter() {
return this.footer;
}
}
제목, 내용, 끝내용은 각각 title, content, footer 필드에 저장된다. 이제 이 데이터를 출력하는 로직을 담당하는 DisplayArticleTemplate 클래스는 다음과 같다.
package pattern;
public abstract class DisplayArticleTemplate {
protected abstract void title();
protected abstract void content();
protected abstract void footer();
protected Article article;
public DisplayArticleTemplate(Article article) {
this.article = article;
}
public final void display() {
title();
content();
footer();
}
}
display 매서드가 로직이고, title, content, footer 매서드가 로직을 구성하는 상세 처리이다. 이제 DisplayArticleTemplate 클래스를 상속해 각 상세 처리를 구현하는 클래스를 살펴보자. 먼저 SimpleDisplayArticle 클래스이다.
package pattern;
import java.util.ArrayList;
public class SimpleArcticle extends DisplayArticleTemplate {
public SimpleArcticle(Article article) {
super(article);
}
@Override
protected void title() {
System.out.println(article.getTitle());
}
@Override
protected void content() {
ArrayList<String> content = article.getContent();
int cntLines = content.size();
for(int i=0; i<cntLines; i++) {
System.out.println(content.get(i));
}
}
@Override
protected void footer() {
System.out.println(article.getFooter());
}
}
다음은 CaptionDisplayArticle 클래스이다.
package pattern;
import java.util.ArrayList;
public class CaptionArticle extends DisplayArticleTemplate {
public CaptionArticle(Article article) {
super(article);
}
@Override
protected void title() {
System.out.println("TITLE: " + article.getTitle());
}
@Override
protected void content() {
System.out.println("CONTENT:");
ArrayList<String> content = article.getContent();
int cntLines = content.size();
for(int i=0; i<cntLines; i++) {
System.out.println(" " + content.get(i));
}
}
@Override
protected void footer() {
System.out.println("FOOTER: " + article.getFooter());
}
}
이제 이 클래스들을 사용하는 코드는 다음과 같다.
package pattern;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
String title = "GIS, powerful tool";
ArrayList<String> content = new ArrayList<String>();
content.add("GIS is a geographic information system.");
content.add("It is base on real spatial data.");
content.add("It provides analyzing spatial and geographic data");
String footer = "2020.10.08, written by Dip2K";
Article article = new Article(title, content, footer);
System.out.println("[CASE-1]");
DisplayArticleTemplate style1 = new SimpleArcticle(article);
style1.display();
System.out.println();
System.out.println("[CASE-2]");
DisplayArticleTemplate style2 = new CaptionArticle(article);
style2.display();
}
}
하나의 데이터에 대해 2가지의 표현 방법을 확인하는 코드인데, 실행 결과는 다음과 같다.
[CASE-1]
GIS, powerful tool
GIS is a geographic information system.
It is base on real spatial data.
It provides analyzing spatial and geographic data
2020.10.08, written by Dip2K
[CASE-2]
TITLE: GIS, powerful tool
CONTENT:
GIS is a geographic information system.
It is base on real spatial data.
It provides analyzing spatial and geographic data
FOOTER: 2020.10.08, written by Dip2K
이 글은 소프트웨어 설계의 기반이 되는 GoF의 디자인패턴에 대한 강의자료입니다. 완전한 실습을 위해 이 글에서 소개하는 클래스 다이어그램과 예제 코드는 완전하게 실행되도록 제공되지만, 상대적으로 예제 코드와 관련된 설명이 함축적으로 제공되고 있습니다. 이 글에 대해 궁금한 점이 있으면 댓글을 통해 남겨주시기 바랍니다.