이 문서는 제가 개인적으로 템플릿을 이용해 코딩할때 참고할 만한 자료를 기재해 놓은 것입니다. 템플릿에 대한 전반적인 내용이 아닌 정리라는 점을 염두해 주시길 바랍니다.
먼저 함수 템플릿의 예이다. Type에 상관 없이 두개의 인자를 받아 이 중 최대값을 반환하는 함수 템플릿의 정의.
tpl_decl.h 라는 파일안에 다음과 같은 코드를 정의 한다.
template T max_Tpl(T a, T b)
{
return (a>b)?a:b;
}typename 대신에 class를 써도 상관없지만, Type이라는 분명한 의미를 제공한다는 점에서 개인적으로 typename을 선호한다. 이 max_Tpl이라는 템플릿 함수는 헤더파일만…. 존재해야한다는 점이… 늘 걸리긴 했지만, 이제 이런 걸림은 그냥 포기하고 받아 들이기로 했다. 구현을 별도의 cpp 파일로 분리하기 위해 export 라는 예약어가 제공된다고 하나.. Visual C++ 2008에서도 예약어로만 선언되어 있을 뿐 아직 구현되어 지원하지 않는다.
위의 max_Tpl이라는 함수의 활용은 아래와 같다.
#include "tpl_decl.h"
int _tmain(int argc, _TCHAR* argv[])
{
double max = max_Tpl(100.0, 200.0);
...위의 코드에서 인자가 실수라는 점이 명확하므로 max_Tpl을 간단히 max_Tpl이라고 해도 되나, 템플릿 함수라는 점을 명확하게 하기 위해 을 붙이는 것을 개인적으로 선호한다.
정의한 max_Tpl이라는 함수에 대해 모든 Type에 대해 작동한다고 보장할 수는 없다. 그 하나의 경우로 문자열 타입에 대한 경우인데, 이 경우 문자열 타입에 대해서는 좀더 특별하게 그 구현을 제공해야한다. 그 구현은 마찬가지로 tpl_decl.h 파일에 아래의 코드를 추가한다.
template<> const char* min_Tpl<>(const char* a, const char *b)
{
return strcmp(a, b)
}이를 함수 템플릿 특수화라 한다.










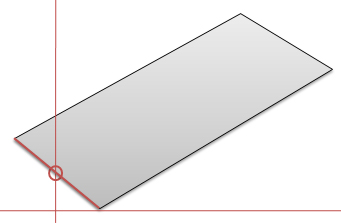
 이 폴리곤에 일정한 높이값을 주어 아래처럼 표현하는 예를 통해 설명하겠습니다.
이 폴리곤에 일정한 높이값을 주어 아래처럼 표현하는 예를 통해 설명하겠습니다.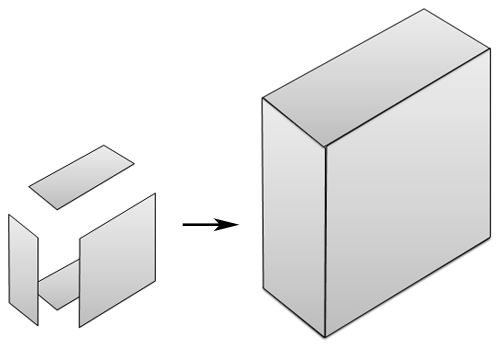 높이값을 주어 위의 그림처럼 표현하기 위해 옆면과 윗면을 높이값을 이용해 그려준 것 뿐입니다. 매우 간단하지요.. 끝?
높이값을 주어 위의 그림처럼 표현하기 위해 옆면과 윗면을 높이값을 이용해 그려준 것 뿐입니다. 매우 간단하지요.. 끝?
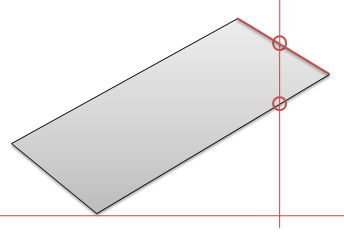
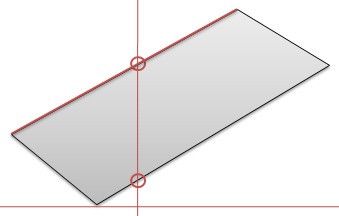
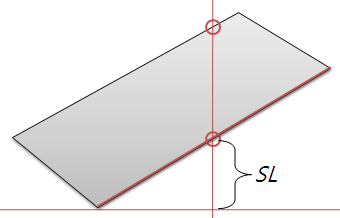 하지만 여기서 중요한 예외 사항이 있는데.. 그것은 처음 기준이 되는 폴리곤을 구성하는 선분과의 중점과 시선축과의 거리(SL)이 선분을 구성하는 시작점이나 끝점과 시선축과의 거리보다 작다면 시선방향선과 교차하지 않는다고 가정을 합니다. 결과적으로 위의 경우는 시선방향선이 2개의 선분과 만나지만 1개만 만나는 것이 됩니다.
하지만 여기서 중요한 예외 사항이 있는데.. 그것은 처음 기준이 되는 폴리곤을 구성하는 선분과의 중점과 시선축과의 거리(SL)이 선분을 구성하는 시작점이나 끝점과 시선축과의 거리보다 작다면 시선방향선과 교차하지 않는다고 가정을 합니다. 결과적으로 위의 경우는 시선방향선이 2개의 선분과 만나지만 1개만 만나는 것이 됩니다.