안녕하세요, GIS Developer 김형준입니다. GIS 프로젝트를 진행하면서 PostgreSQL을 많이 사용하게 되는데요. 프로젝트에서 PostgreSQL를 사용하면서 점진적으로 더 나은 개발 방법을 찾게되었고, 더 나은 개발 생산성과 개발하고자 하는 시스템의 안정성과 퍼포먼스를 위해 Trigger와 Stored Procedure를 도입하게 되었습니다.
이 글은 Stored Procedure에 대한 강좌 형식으로 정리하는 글입니다. PostgreSQL는 프로그래밍 언어를 이용해 함수를 직접 만들어 실행하기 위해 PL/pgSQL이라는 언어를 제공합니다. 이 PL/pgSQL를 활용한다는 것이 바로 Stored Procedure를 사용한다는 것이고, 이를 이용해 Trigger를 사용할 수 있는 발판이 됩니다.
PL/pgSQL은 PostgreSQL을 보다 편리하고 빠른 응답성을 제공받기 위해 사용할 수 있을 뿐만 아니라 데이터베이스 자체의 기능을 확장할 수 있는 기반을 제공합니다. PostgreSQL의 Stored Procedure 개발을 위한 언어가 비단 PL/pgSQL만 가능한 것은 아닌데요, 특히 C언어를 통해서도 개발이 가능하지만, 이 글에서는 PL/pgSQL에만 집중하도록 하겠습니다.
먼저 PostgreSQL의 Stored Procedure를 사용하면 얻을 수 있는 장점을 정리하면 다음과 같습니다.
- 여러개의 SELECT나 UPDATE, INSERT 등과 같은 Query 문을 Stored Procedure 문을 통해 하나로 묶어 실행함으로써 서버와 클라이언트 간의 Round Trip의 개수를 줄여 줍니다. 이러한 Round Trip을 줄이면 불필요한 네트워크 통신 횟수를 줄여 더 빠르게 DBMS 연산 결과를 얻을 수 있습니다.
- SELECT나 UPDATE, INSERT, DELETE 문 등을 Java의 JDBC 등을 이용해 실행하게 되면, Query 문을 해석하고 실행하기에 앞서 많은 준비가 필요한데요. Stored Procedure는 이미 컴파일되어 DBMS 단에서 바로 실행할 수 있도록 준비되어 있어 그 실행 속도가 매우 빠르며, 함수 호출 시 인자만을 변경하여 빠르고 쉽게 재활용이 가능합니다.
PostgreSQL의 장점이 있다면, 단점도 있겠지요. 단점을 언급해 본다면 다음과 같습니다.
- Stored Procedure를 C나 PL/pgSQL과 같은 프로그래밍 언어로 개발해야 하므로 특별환 스킬을 요구하고, 문제 발생시 디버깅이 어렵습니다.
- Stored Procedure는 표준인 SQL과는 다르게 DBMS 마다 다르므로 DBMS가 변경되면 해당 DBMS에 맞게 Stored Procedure를 다시 개발해야 합니다.
자, 이제 PL/pgSQL을 이용해 간단한 Stored Procedure를 만들어 보도록 하겠습니다. 사용자 정의 함수를 만들기 위해서는 CREATE FUNCTION 문을 사용하는데요. 그 문법은 아래와 같습니다.
CREATE FUNCTION function_name(param1 type, param2 type) RETURNS return_type AS BEGIN -- code END; LANGUAGE language_name;
위의 코드를 좀더 상세히 설명하면 function_name은 함수의 이름이고 param1 type과 param2 type는 함수의 인자를 의미합니다. 여기서는 2개이고 인자의 이름은 param1, param2이며, 인자명 바로 뒤에는 인자의 타입이 옵니다. return_type에는 이 함수의 반환값의 타입을 의미합니다. BEGIN과 END 사이의 — code에 이 함수가 실행할 코드를 입력하면 됩니다. 그리고 마지막으로 language_name에는 이 함수에 대한 프로그래밍 언어가 무엇인지를 나타내는데, 여기서 우리는 PL/pgSQL 언어를 사용하므로 항상 plpgsql이 됩니다.
이제 Stored Procedure를 만들기 위한 CREATE FUNCTION 구문에 대한 문법을 모두 살펴보았으므로, 실제 간단한 함수를 만들어 보겠습니다.
만들고자 하는 함수는 2개의 정수를 입력받아 합한 결과를 반환해 주는 함수입니다.
CREATE FUNCTION add(a INTEGER, b INTEGER)
RETURNS INTEGER AS
$$ BEGIN
RETURN a+b;
END; $$
LANGUAGE PLPGSQL;
위의 코드를 pgAdmin 툴에서 입력하고 실행하면 functions에 add라는 함수가 새롭게 추가된 것을 볼 수 있습니다.
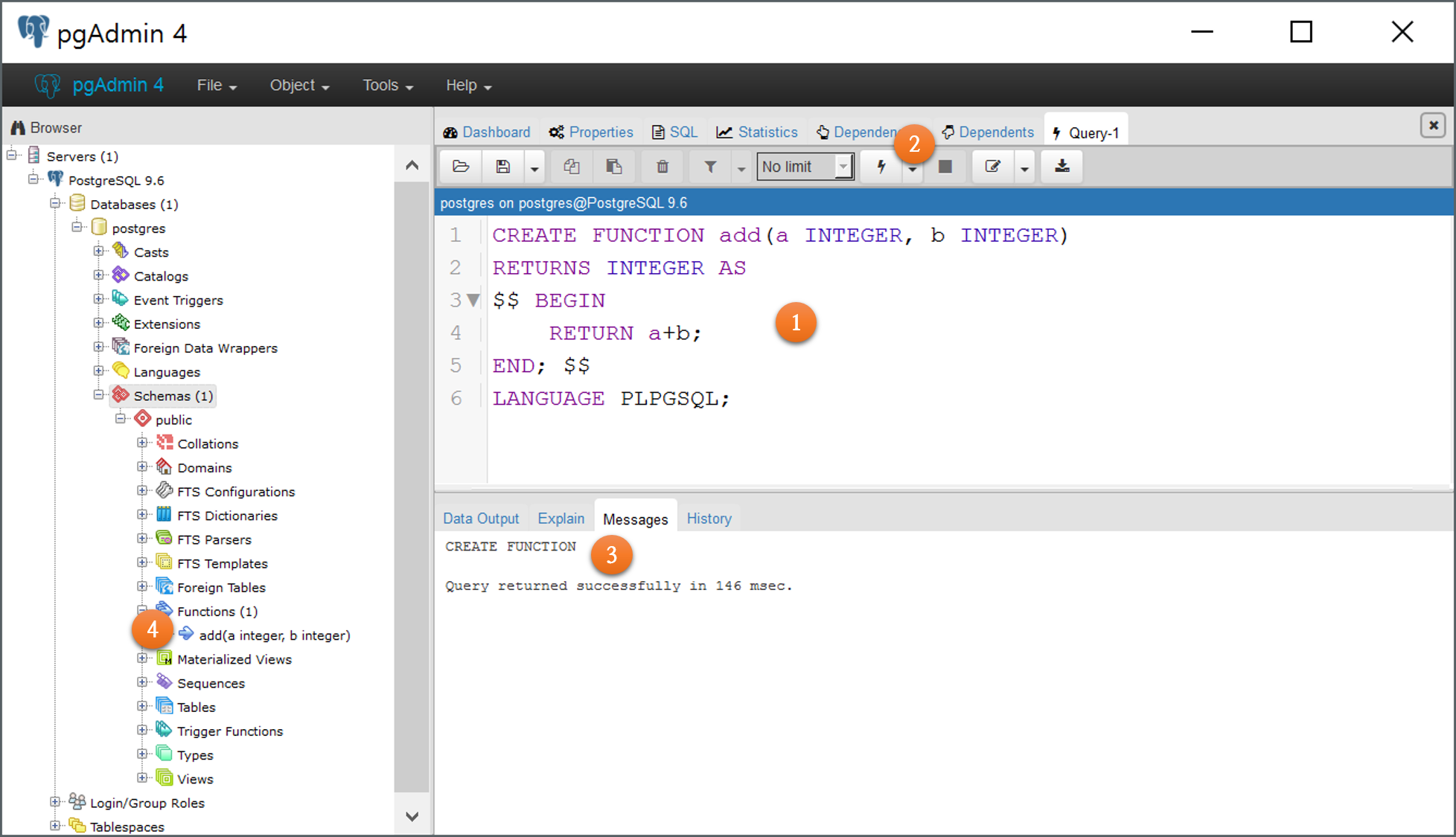
위의 그림은 실제 위의 add 함수를 pgAdmin에서 입력하고 실행하여 새로운 Function을 등록한 모든 내용을 담고 있습니다. 위의 그림에서 (1)은 함수를 생성하기 위한 CREATE FUNCTION을 입력하고 (2)는 함수를 생성하도록 입력된 CREATE FUNCTION 문을 실행하고 (3)은 그 실행 결과이며 (4)는 등록에 성공했을때 추가되는 add 함수입니다.
이렇게 추가된 add 함수는 다음처럼 실행해 그 결과를 볼 수 있습니다.
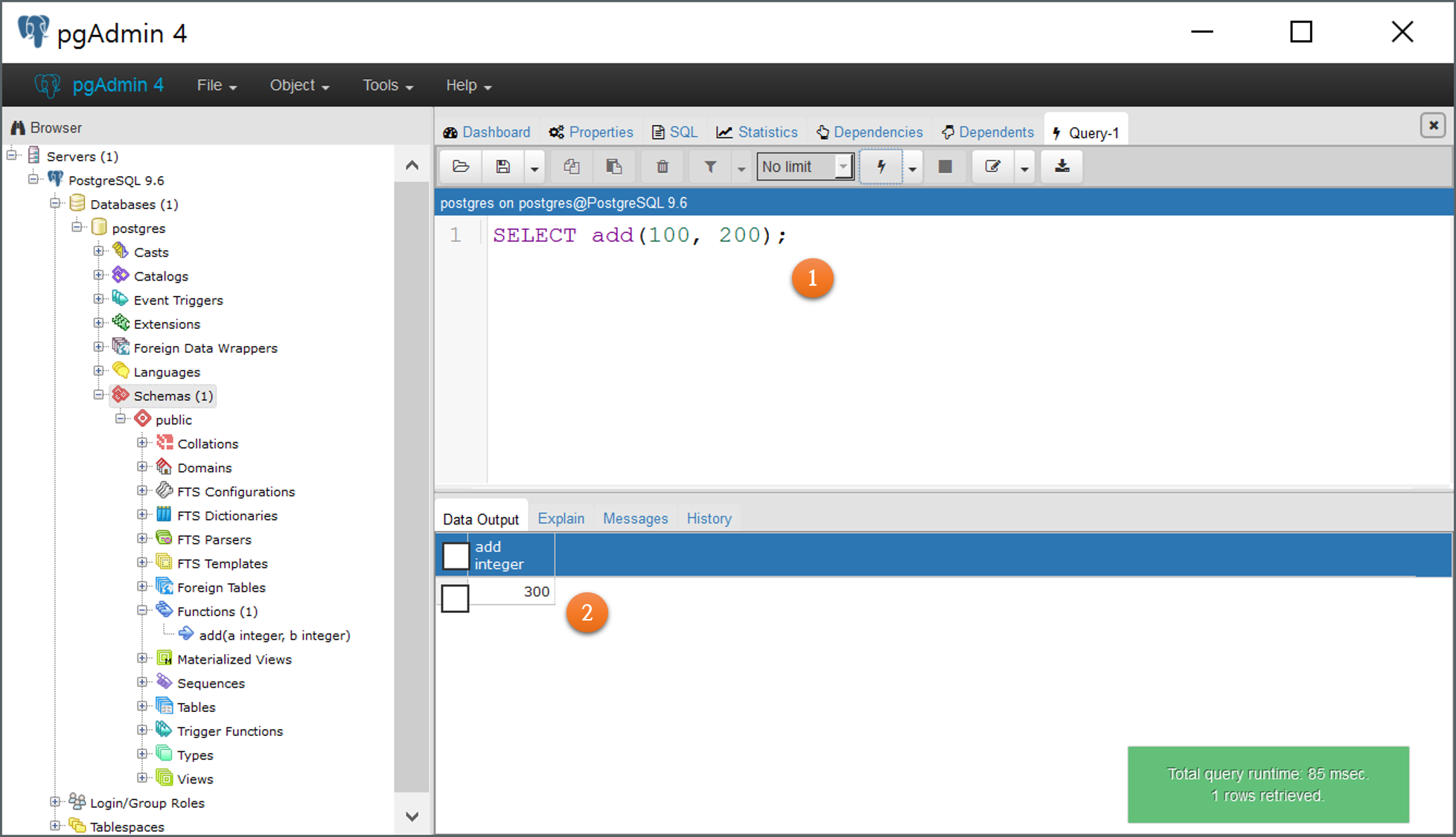
이상으로 PostgreSQL에서 Stored Procedure의 소개와 장단점에 대해 알아봤고, PG/pgSQL을 이용해 간단한 사용자 정의 함수를 만들어 보았습니다.