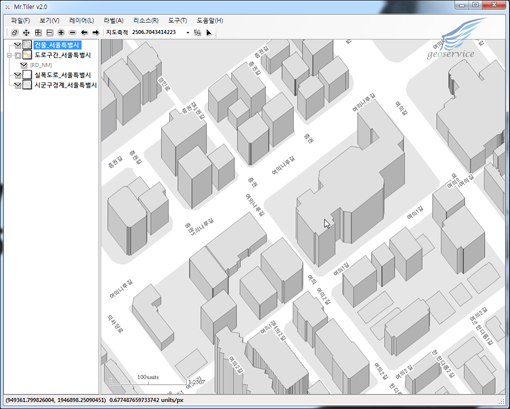
핑거아이즈가 OGC 표준 맵 서비스인 WMS를 지원하게 되었습니다. 지원에 대한 테스트 WMS 버전은 1.1.1입니다. 아래는 핑거아이즈에서 WMS를 통해 지적도를 서비스 받아 표시한 화면입니다.
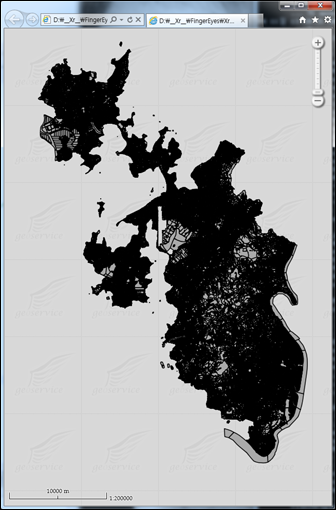
테스트에 대해 사용한 공간서버는 GeoServer 2.1.1입니다. GeoServer에 대한 셋팅과 SHP 파일을 통한 레이어 구성등은 On Spatial(www.onspatial.com) 블로그에서 제공하는 문서(http://ss.textcube.com/blog/3/30800/attach/XVnDChhGSs.pdf)를 참고하여 진행하였습니다. 아래는 위의 지적도를 표출을 위해 서비스 되고 있는 GeoServer의 실행 화면입니다.
WMS에 대한 내용의 이해는 OGC에서 제공하는 OpenGIS Web Map Server Implementation Specification 문서를 통해 파악하였습니다. 끝으로 핑거아이즈에서 WMS를 통한 레이어를 추가하는 코드는 아래와 같습니다.
var lyr:XrWMSLayer = new XrWMSLayer(
"wmsLyr",
"http://www.gisdeveloper.co.kr:8080/geoserver/wms",
"MyWorkspace:JIBUN_SINGLE",
"EPSG:2097");
map.layers.addLayer(lyr);