업무중에 필요해서 작성한 쿼리문을 기록해 둡니다.

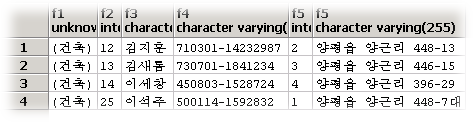
2~7번은 조회하고자 하는 필드와 알리아스(Alias)입니다. 알리아스는 단순히 이름이므로 중복이 가능합니다. 9~10번은 조회 대상이 되는 테이블과 그에 대한 알리아스입니다. 12~21번은 검색 조건입니다. 결과는 아래와 같습니다.
혹시.. 퍼포먼스를 향상시킬 수 있는 개선할 점이나.. 문제가 되는 부분이 있으면 피드백 부탁드립니다.

공간정보시스템 / 3차원 시각화 / 딥러닝 기반 기술 연구소 @지오서비스(GEOSERVICE)
업무중에 필요해서 작성한 쿼리문을 기록해 둡니다.
2~7번은 조회하고자 하는 필드와 알리아스(Alias)입니다. 알리아스는 단순히 이름이므로 중복이 가능합니다. 9~10번은 조회 대상이 되는 테이블과 그에 대한 알리아스입니다. 12~21번은 검색 조건입니다. 결과는 아래와 같습니다.
혹시.. 퍼포먼스를 향상시킬 수 있는 개선할 점이나.. 문제가 되는 부분이 있으면 피드백 부탁드립니다.
핑거아이즈는 공간서버인 지오서비스(GeoService-Xr)의 지오프로세싱(Geoprocessing) 서비스를 통해 지오메트리의 버퍼 연산을 수행할 수 있습니다. 아래의 코드는 레이어의 구성 항목 중 하나의 도형에 대해 버퍼 반경값 10으로 하여 버퍼 연산을 수행하는 코드입니다.
var ml:XrMashupLayer = _map.layers.getLayer("myLyr") as XrMashupLayer;
var mashup:IXrMashup = ml.getMashup(0);
if(mashup != null)
{
var wkt:IXrWKT = mashup as IXrWKT;
var strKwt:String = wkt.toWKT();
var loader:URLLoader = new URLLoader();
var url:String = "http://www.gisdeveloper.co.kr/Gp?command=buffer;geometry="
+ strKwt + ";distance=10";
var request:URLRequest = new URLRequest(url);
loader.addEventListener(Event.COMPLETE, onBufferRequestCompleted);
loader.load(request);
}
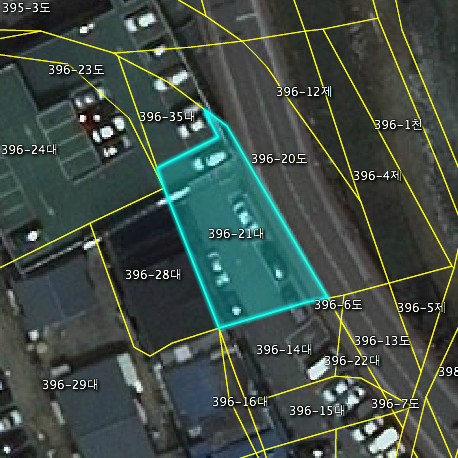
1번과 2번 코드를 통해 버퍼 연산 대상이 되는 도형을 가져옵니다. 그리고 이 도형에 대한 지오메트리 정보를 WKT 형식으로 변환하는 코드가 5~6번 코드입니다. 마지막으로 7~13번 코드를 통해 공간서버로 요청을 날립니다. 아래의 이미지는 버퍼 연산의 대상이 되는 도형입니다.
버퍼 연산 서비스를 요청하고 그 결과는 onBufferRequestCompleted 함수를 통해 전달되며 다음과 같은 예로 구성될 수 있습니다.
private function onBufferRequestCompleted(event:Event):void
{
var loader:URLLoader = event.target as URLLoader;
var result:String = loader.data;
var ml:XrMashupLayer =
_map.layers.getLayer("myLyr") as XrMashupLayer;
var mashup:IXrMashup = ml.getMashup(0);
if(mashup != null)
{
var wkt:IXrWKT = mashup as IXrWKT;
wkt.fromWKT(result);
ml.updateItem(0, false);
}
loader.removeEventListener(Event.COMPLETE, onBufferRequestCompleted);
}
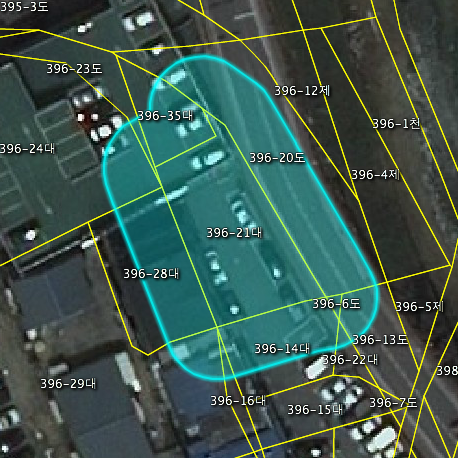
버퍼 연산 결과에 대한 지오메트리 역시 WKT 형식입니다. 연산 결과를 다시 대상이 되는 도형에 반영하고 있습니다. 그 결과는 다음과 같습니다.
Geometry로 Feature를 가져온다는 의미는 임의의 지오메트리와 공간상에서 교차하는 Feature를 가져온다는 의미입니다. 임의의 지오메트리이므로 폴리곤, 폴리라인, 포인트 등 제약이 없습니다. 기준 지오메트리는 WKT 형식으로 쉽게 지정할 수 있습니다. 다음은 지정한 폴리라인과 교차하는 Feature를 서버측으로부터 가져오라는 코드 예입니다.
var pnuLyr:XrShapeMapLayer = map.layers.getLayer("JIBUN") as XrShapeMapLayer;
if(pnuLyr != null)
{
var bOK:Boolean = pnuLyr.queryByGeometry(
"LINESTRING(250661 54225, 250343 53233)",
true,
callback);
if(!bOK)
{
// Error !
}
}
대상이 되는 레이어를 1번 코드를 통해 가져옵니다. 속성과 도형에 대한 기능이므로 XrShapeMapLayer만이 가능합니다. 그리고 4번에서 queryByGeometry 매서드를 통해 쿼리 합니다. 첫번째 인자는 기준 지오메트리로써 WKT 형식으로 지정합니다. 그리고 두번째 인자는 도형 데이터 뿐만 아니라 속성 데이터까지 가져오라는 의미입니다. 그리고 세번째 인자는 공간 데이터 쿼리가 완료되었을때 발생하는 콜백함수이며 아래는 그 예입니다.
private function callback(arg:XrSpatialQueryResult):void
{
if(arg != null)
{
var shp:IXrShape = null;
var shapes:Object = arg.shapeSet.rows;
for each(shp in shapes)
{
var attribute:XrAttributes =
arg.attributeSet.rows[shp.fid] as XrAttribute;
if(attribute != null)
{
trace(shp.centroid.x + " " + shp.centroid.y
+ " " + attribute.getValueAsString(1));
}
}
}
else
{
// 아무것도 오질 않았음..
}
}
서버 측으로 받은 결과에서 도형의 중심점과 2번째 속성값만을 확인하는 예입니다.
FID값은 FeatureID로써 이 값에 대한 Feature를 가져오는 예제 코드입니다. 참고로 Feature는 공간 데이터 + 속성 데이터의 셋입니다.
var pnuLyr:XrShapeMapLayer = map.layers.getLayer("JIBUN") as XrShapeMapLayer;
if(pnuLyr != null) {
var fids:Vector. = new Vector.();
fids.push(100, 200, 300, 400, 500, 600, 700, 10000);
if(!pnuLyr.queryByFIDs(fids, true, callback))
{
// Query Request Error !!
}
}
먼저 대상 레이어를 파악해야 합니다. FID에 관련된 레이어이므로 1번 코드에서 XrShapeMapLayer가 필요하고 요청할 FID의 리스트를 3~4번에서 만들고 있습니다. 그리고 5번 코드에서 queryByFIDs 매서드를 통해 리퀘스트를 서버에 날립니다.
서버에 대한 응답은 비동기적으로 처리되므로 콜백함수가 필요하며 queryByFIDs의 세번째 인자에 지정합니다. 두번째 인자는 공간 데이터 뿐만 아니라 속성 데이터까지 가져오라는 의미입니다. 그렇다면 서버로부터 받은 Feature를 처리하기 위한 콜백함수를 살펴보면, 그 예는 다음과 같습니다.
private function callback(arg:XrSpatialQueryResult):void
{
if(arg != null)
{
var shp:IXrShape = null;
var shapes:Object = arg.shapeSet.rows;
for each(shp in shapes)
{
var attribute:XrAttributes =
arg.attributeSet.rows[shp.fid] as XrAttribute;
if(attribute != null)
{
trace(shp.centroid.x + " " + shp.centroid.y
+ " " + attribute.getValueAsString(1));
}
}
}
else
{
// 아무것도 오질 않았음..
}
}
결과가 오면 도형의 중심점과 두번째 속성값을 표시하는 코드입니다.
핑거아이즈는 서버측의 DBMS에 UPDATE, INSERT, DELETE와 같은 SQL 문을 실행할 수 있도록 요청할 수 있습니다. 다음 코드는 그 예입니다.
var svc:XrUpdateTableService = new XrUpdateTableService(
"127.0.0.1:8076",
"postgis",
__completed,
__error
);
var sql:String = "INSERT INTO tstTbl VALUES (100, '안녕하세요!')";
svc.run({sql:sql});
SQL문의 실행을 서버측에 요청하고 그 결과를 받아오는 일련의 과정을 사용하기 쉽게 캡슐화된 XrUpdateTableService 클래스를 이용합니다. 서버의 IP와 사용하는 DBMS의 종류 그리고 SQL 문이 서버측에서 성공적으로 실행되었을때와 실패했을때에 대한 콜백함수를 생성자의 인자로 지정합니다.
아래는 SQL문이 성공적으로 실행되었을때와 실패했을때에 대한 콜백함수의 예입니다.
protected function __completed(cntRowUpdated:uint):void
{
// cntRowUpdated는 SQL문의 실행에 의해 영향을 받은 Row의 수
}
protected function __error():void
{
// SQL 실행하는데 문제 있음
}