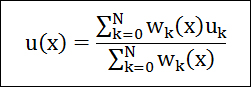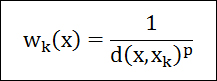지형이라는 주제로 제작된 라스터(Raster)의 셀(Cell)에 기반한 분석 중 경사(Slope)와 향(Aspect) 분석은 중요한 자리를 차지하며, 이 경사와 향은 지형에 대한 분석 및 응용의 파라메터로 사용됩니다. 이 글은 개발 중인 지도 엔진의 확장 기능의 하나로써 경사와 향을 분석하는 것과 이 경사와 향을 분석하는 기능을 응용하여 다시 지형의 음영도(Hillshade)를 만드는 확장 기능에 대한 소개입니다. 여기서 확장 기능이란 지도 엔진과는 별개의 파일 단위로써 엔진에 플러그인하여 별도의 스레드를 통해 실행시킬 수 있는 외부의 확장 실행 단위 모듈입니다.
경사와 향 값을 분석하기 위해서는 분석 대상이 되는 지역에 대한 DEM 데이터가 필요합니다. 이 DEM의 라스터 데이터로써 아래와 같은 데이터를 사용하였습니다.
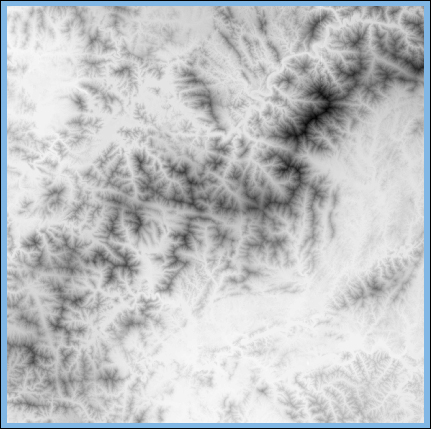
이 데이터는 김한국님이 운영하는 비지니스 GIS 커뮤니티(www.biz-gis.com)에서 내려 받은 데이터입니다. 그리고 위의 이미지를 포함해서 앞으로 나오는 지도 화면은 모두 오픈메이트(www.openmate.co.kr)의 개발한 맵 엔진으로 생성한 화면입니다. 위의 데이터를 통해 경사값과 향을 계산하기 전에 간단히 경사와 향이 무엇인지에 대해 언급하겠습니다.
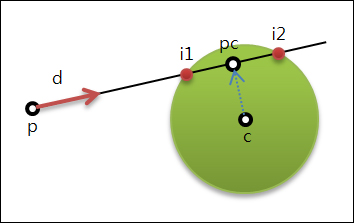
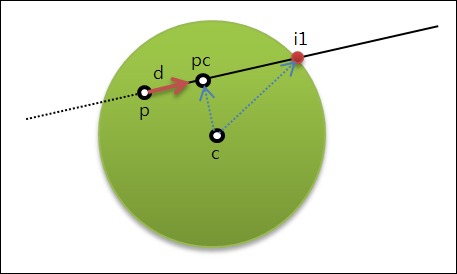
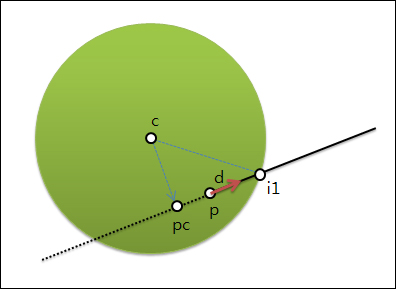
경사(Slope)란 어떤 지점의 지반이 수평을 기준으로 몇도 정도 기울어져 있는가를 말하는 것으로 다음 그림을 통해 쉽게 이해할 수 있을 것입니다.
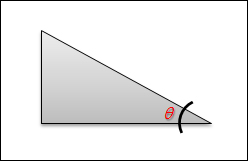
바로 저 세타 각도가 경사 기울기에 대한 각도로써 각이 클 수록 지반의 경사가 급하고 각이 0이면 평편한 지반임을 나타냅니다.
향(Aspect)이란 지반의 경사면이 어디를 향하고 있는지에 대한 것입니다. 만약 지반의 경사면이 북쪽을 향하고 있다면 0도, 동쪽은 90도, 남쪽은 180도 그리고 서쪽은 270도가 됩니다. 완전히 평편할 경우 GIS 시스템마다 다른 값을 주게 되는데, 여기서는 Null 값을 줍니다. (사실 Null은 값이 없다는 의미이므로, 좀더 정화하게 한다면 0~360이 아닌 다른 값을 주어야 옳습니다. 예를들어서 -1과 같은 값이 적당하겠습니다)
실제로 구현된 경사와 향에 대한 실행 결과는 아래와 같습니다. 각각 경사와 향에 대한 이미지입니다.

가만이 보면 향의 분석 결과가 불완전하기는 하지만 음영기복도(Hillshade)와 비슷해 보입니다. 여기서 Hillshade는 태양광의 위치를 정해주면 태양광의 영향으로 지형 데이터를 입체감 있게 표현해 주는 방법입니다. 아래는 이러한 내용으로 개발한 맵 엔진에 구현된 Hillshade의 결과입니다.

태양의 위치는 북동쪽(270)이고 고도는 45도로 정했습니다. 위의 Hillshade의 결과는 비록 입체적으로 보이기는 하지만 마치 석고를 발라 놓은 듯이 매우 딱딱해 보입니다. 이를 좀더 예술적(?)으로 표현하기 위해 이 글의 가장 처음 보여드렸던 지형 데이터의 원본 이미지와 위의 Hillshade를 합성하게 되는데, 좀더 멋진 음영기복도를 위한 합성 방법은 Hillshade을 약간 투명하게 하고 Luminosity 방식으로 합성해야 하나, 개발한 맵 엔진에서는 Luminosity 방식의 합성을 지원하지 않아 그냥 투명도만 주어 새롭게 음영기복도를 만들어 보았습니다. 그 결과는 아래와 같습니다.

봄 계절에 맞게 색상을 넣어 보았습니다. 좀더 색상을 다체롭게 넣는다면 더 멋진 음영기복도 만들어 질 것으로 판단되며, 앞서 언급한 Luminosity 합성을 사용하면 보다 분명한 음영기복도가 만들어 질 것 입니다. 이상으로 개발한 맵 엔진에서 확장기능으로 개발한 경사, 향 그리고 Hillshade에 대한 소개를 마칩니다.