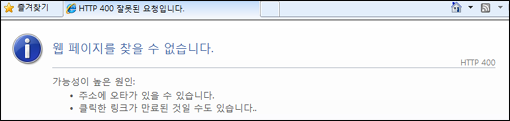
수년전에 오렐리라는 출판사에서 나온 자바의 2D API를 보면서… 이 API를 이용해 2D GIS 엔진을 자바로 만들면 정말 환상이겠구나… 라는 생각을 했던 적이 있었습니다. 그런데.. 안드로이드를 살펴보면서 또 다시 이런 생각이 다시 듭니다.. 안드로이드가 내세우는 주요 개발 언어가 자바라는 점과 이러한 생각은 우연이 일치이겠지만 말입니다. 또 다시 이러한 생각을 들게 만드는 안드로이드의 기능은 아래와 같은 기능 때문입니다. 즉, Path을 따라 사용자가 표현하고자 하는 텍스트를 자연스럽게 회전시켜주는 기능입니다.

참으로.. 아름답습니다! 그럼 어떻게 이렇게 하는지 안드로이드 맛보기 겸해서 코드를 잠시 살펴보도록 하겠습니다. 물론 안드로이드를 잘 아시는 분들은 걍.. 살짝 패스해주셔도 됩니다!
먼저 간단히 View를 하나 만듭니다. View 클래스는 안드로이드에서 위젯(UI 컨트롤)을 나타내는데 유용한 부모클래스입니다..
public class MyView extends View {
public MyView(Context context) {
super(context);
}
public void onDraw(Canvas canvas) {
Path path = new Path();
canvas.drawColor(Color.BLACK);
Paint Pnt = new Paint();
Pnt.setAntiAlias(true);
Pnt.setStrokeWidth(1);
Pnt.setColor(Color.GREEN);
Pnt.setStyle(Paint.Style.STROKE);
path.moveTo(10, 10);
path.cubicTo(80, 150, 100, 220, 310, 410);
Pnt.setColor(Color.GREEN);
canvas.drawPath(path, Pnt);
Pnt.setTextSize(40);
Pnt.setStrokeWidth(1);
Pnt.setStyle(Paint.Style.FILL);
Pnt.setColor(Color.WHITE);
Pnt.setAntiAlias(true);
canvas.drawTextOnPath("안드로이드의 패스위 문자열 표현", path, 0, 0, Pnt);
}
}
즉, 문자열이 표시될 방향을 결정할 Path 객체를 만들어주고.. Canvas의 drawTextOnPath 매서드를 통해 원하는 문자열을 표시해주기만 하는.. 매우 효율적인 API를 제공합니다. 이제 이 View를 실제로 사용하는 Activity를 정의합니다.
public class UseMyView extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
MyView vw = new MyView(this);
setContentView(vw);
}
}
안드로이드에서 Activity는 실제로 화면에 표시되지는 않지만 화면을 구성하는 가장 핵심이 되는 단위로.. View를 컨트롤하여 화면에 개발자가 원하는 컨텐츠를 표시할 수 있습니다. 안드로이드의 2D 그래픽스…. 많은 모바일 API를 경험해 보지는 않았으나… 정말 이 정도로 뛰어난 2D 그래픽 API를 제공하는 모바일 개발 플랫폼이 있을까… 싶습니다..