패턴 명칭
Worker Thread
필요한 상황
어떤 데이터가 생성되면, 이 데이터를 또 다른 여러 개의 스레드에서 처리한다. 물론 데이터의 생성 역시 또 다른 여러 개의 스레드에서 처리한다. 데이터의 처리를 동시에 처리하면서 처리하는 방식은 한가지로 정해진 것이 아닌 다양한 방식으로 수행되며, 간단이 추가될 수 있어야 한다. 이때 사용할 수 있는 패턴이다. 사실, 데이터의 다양한 방식의 처리는 Worker Thread의 응용이다.
예제 코드
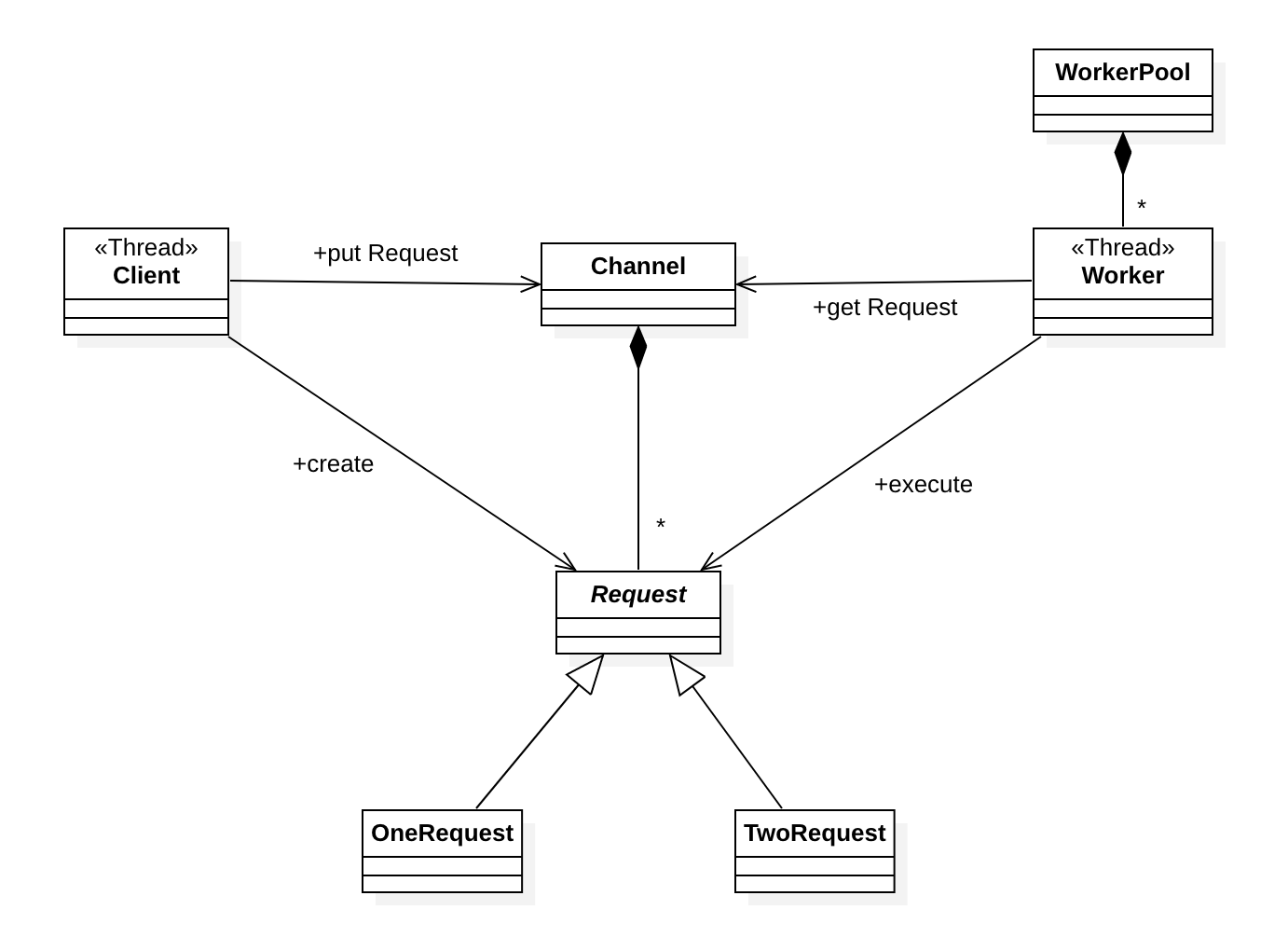
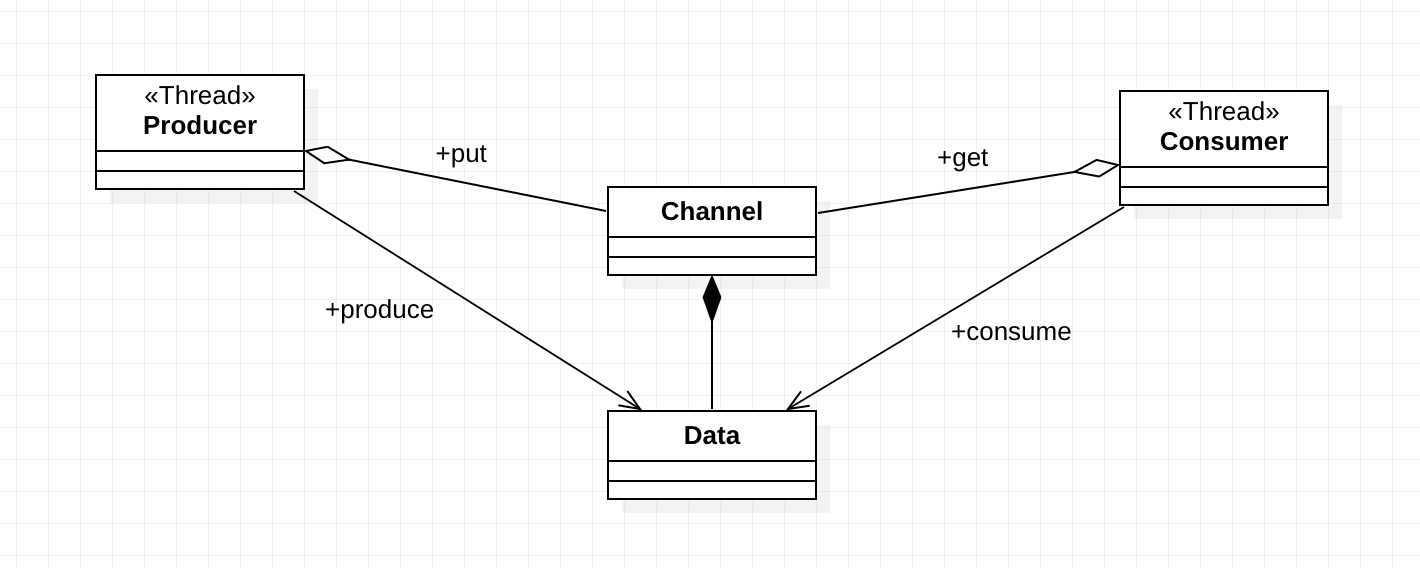
Client 클래스는 처리할 데이터를 생성한다. 이렇게 생성된 데이터는 Request라는 클래스에 담기게 되는데 이 Request는 추상 클래스이며, 이 클래스를 상속받아 데이터에 대한 처리 방식을 정의할 수 있다. Client가 생성한 Request는 바로 처리되는게 아니고 Channel 클래스에 저장된다. 이렇게 저장된 데이터에 대한 Request는 Worker 클래스에의해 스레드로 처리된다. 이 Worker 클래스는 WorkerPool이라는 스레드 저장소에 미리 생성되어 관리된다. 이러한 클래스들을 사용하는 코드는 다음과 같다.
package tstThread;
public class Main {
public static void main(String[] args) {
Channel channel = new Channel(10);
WorkerPool workers = new WorkerPool(5, channel);
workers.start();
new Client("ClientA", channel).start();
new Client("ClientB", channel).start();
new Client("ClientC", channel).start();
}
}
Channel에 최대로 저장할 수 있는 Request의 개수는 10개, 데이터를 처리하는 Worker의 개수는 5개로 정했으며, 데이터를 생성하는 Client 스레드의 개수는 3개이다. Client 클래스의 코드는 다음과 같다.
package tstThread;
import java.util.Random;
public class Client extends Thread {
private final Channel channel;
private static final Random random = new Random();
public Client(String name, Channel channel) {
super(name);
this.channel = channel;
}
public void run() {
try {
for(int i = 0; true; i++) {
Request request;
Thread.sleep(random.nextInt(1000));
if(random.nextInt(2) == 0) {
request = new OneRequest(getName(), i);
} else {
request = new TwoRequest(getName(), i);
}
channel.putRequest(request);
}
} catch(InterruptedException e) {
//.
}
}
}
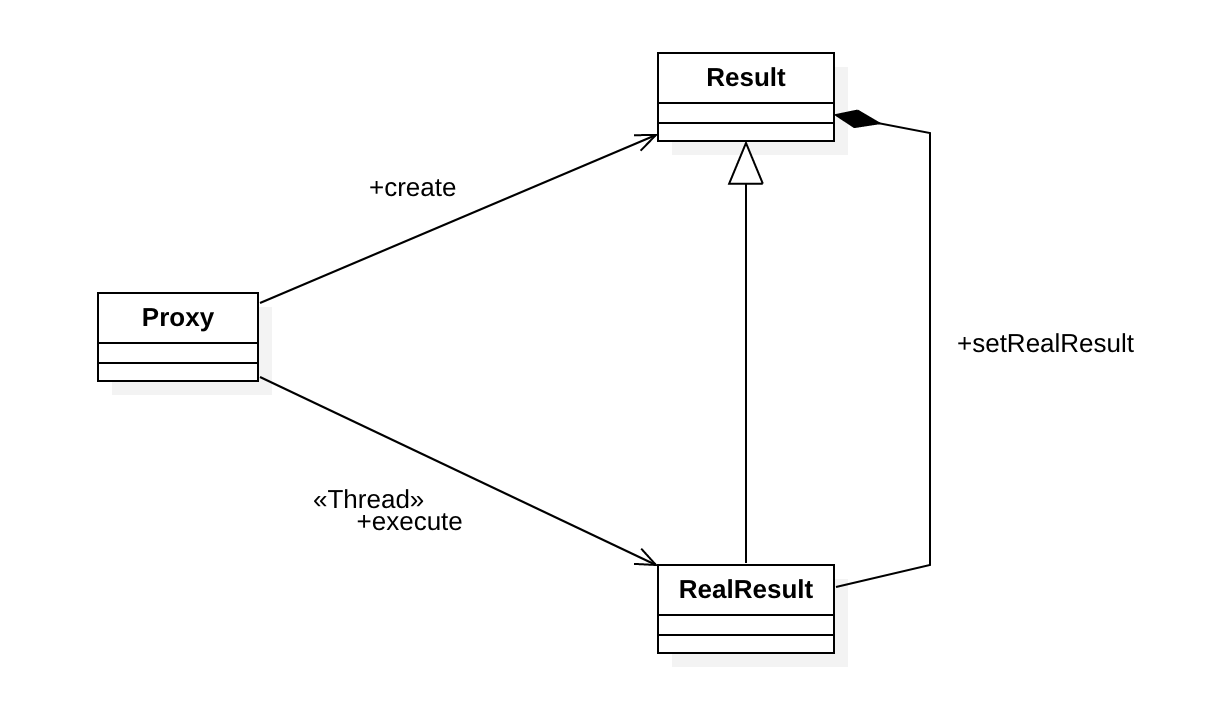
처리해야할 데이터는 정수값이며, 이 정수값의 데이터에 대한 처리는 무작위로 결정되는데, 실제 처리에 대한 코드는 OneRequest와 TwoRequest 클래스에 정의되어 있다. Request 추상 클래스에 대한 코드는 다음과 같다.
package tstThread;
public abstract class Request {
protected final String clentName;
protected final int number;
public Request(String clentName, int number) {
this.clentName = clentName;
this.number = number;
}
public abstract void execute();
}
이 추상클래스를 구현하는 OneRequest 클래스는 다음과 같다.
package tstThread;
public class OneRequest extends Request {
public OneRequest(String name, int number) {
super(name, number);
}
public void execute() {
String result = "ECHO: " + number + "@" + clentName;
System.out.println(Thread.currentThread().getName() + " -> " + result);
}
}
또 다른 처리 방식인 TwoRequest 클래스는 다음과 같다.
package tstThread;
public class TwoRequest extends Request {
public TwoRequest(String name, int number) {
super(name, number);
}
public void execute() {
String result = "POWER: " + (number*number) + "@" + clentName;
System.out.println(Thread.currentThread().getName() + " -> " + result);
}
}
이 Request 클래스에 대한 객체는 Client가 생성하여 Channel에 저장되는데, Channel 클래스의 코드는 다음과 같다.
package tstThread;
import java.util.LinkedList;
public class Channel {
private final int maxCountRequests;
private final LinkedList<Request> requestQueue = new LinkedList<Request>();
public Channel(int maxCountRequests) {
this.maxCountRequests = maxCountRequests;
}
public synchronized void putRequest(Request request) {
while(requestQueue.size() >= maxCountRequests) {
try {
wait();
} catch(InterruptedException e) {
//.
}
}
requestQueue.addLast(request);
notifyAll();
}
public synchronized Request takeRequest() {
while(requestQueue.size() <= 0) {
try {
wait();
} catch(InterruptedException e) {
//.
}
}
Request request = requestQueue.pollFirst();
notifyAll();
return request;
}
}
데이터를 처리하는 Worker 클래스는 다음과 같다.
package tstThread;
public class Worker extends Thread {
private final Channel channel;
public Worker(String name, Channel channel) {
super(name);
this.channel = channel;
}
public void run() {
while(true) {
Request request = channel.takeRequest();
request.execute();
}
}
}
Worker 클래스의 객체는 WorkerPool이라는 클래스를 통해 생성되어 관리되며 코드는 다음과 같다.
package tstThread;
public class WorkerPool {
private final Worker[] threadPool;
public WorkerPool(int countThreads, Channel channel) {
threadPool = new Worker[countThreads];
for(int i=0; i<threadPool.length; i++) {
threadPool[i] = new Worker("Worker-" + i, channel);
}
}
public void start() {
for(int i=0; i<threadPool.length; i++) {
threadPool[i].start();
}
}
}
실행 결과는 다음과 같다.
Worker-0 -> ECHO: 0@ClientA
Worker-4 -> ECHO: 0@ClientB
Worker-3 -> POWER: 0@ClientC
Worker-2 -> POWER: 1@ClientB
Worker-3 -> POWER: 4@ClientB
Worker-2 -> POWER: 1@ClientC
.
.
.
orker-0 -> POWER: 625@ClientC
Worker-2 -> POWER: 784@ClientB
Worker-0 -> POWER: 841@ClientB
Worker-2 -> POWER: 784@ClientA
Worker-0 -> POWER: 841@ClientA
Worker-2 -> ECHO: 30@ClientB
Worker-0 -> POWER: 676@ClientC
Worker-2 -> ECHO: 30@ClientA
Worker-3 -> POWER: 961@ClientA
Worker-2 -> ECHO: 32@ClientA
Worker-3 -> POWER: 961@ClientB