XML 데이터를 쓰고 읽기 위해서 인터넷을 검색하던 차에 속도를 강점으로 내세우면서 STL 만을 사용하여 플랫폼 이식에도 뛰어난 오픈소스를 찾았는데요. 바로 CMarkup 입니다. 다운로드 사이트는 http://www.firstobject.com/ 이구요. 사용해 보니 XML의 charset도 지원하여 더욱 믿음이 가는 오픈소스였습니다. XML을 처리할 일이 있다면 한번 사용해 보시기 바랍니다.
추후 이 오픈소스를 다시 사용할 때를 대비하여 사용 방법을 정리해 정리차원에서 올려봅니다.
컴파일 시 주의할 사항은… CMarkup은 MFC의 CString와 STL의 string에 대한 문자열 타입을 사용하며 기본적으로 CString을 사용합니다. 플랫폼에 독립적인 구성을 위해서 STL을 사용하는것이 좋기 때문에 전처리에서 MARKUP_STL를 정의해줘야 합니다. 이 전처리 정의는 프로젝트의 속성 페이지에서 해줌으로써 전역적으로 적용되도록 해야 합니다. 아래의 코드는 XML을 쓰는 예제 코드입니다. 윈도우즈 계열의 개발툴인 VS2008로 작성했습니다.
#include "stdafx.h"
#include "../Markup.h"
int _tmain(int argc, _TCHAR* argv[])
{
CMarkup xml;
xml.AddElem( "ORDER" );
xml.AddChildElem( "ITEM" );
xml.IntoElem();
xml.AddAttrib("type", "A");
xml.AddChildElem( "SN", "132487A-J" );
xml.AddChildElem( "NAME", "crank casing" );
xml.AddChildElem( "QTY", "1" );
xml.OutOfElem();
xml.AddChildElem( "ITEM" );
xml.IntoElem();
xml.AddAttrib("type", "C");
xml.AddChildElem( "SN", "434417F-Y" );
xml.AddChildElem( "NAME", "kully casing" );
xml.AddChildElem( "QTY", "2" );
xml.OutOfElem();
std::string csXML = xml.GetDoc();
printf("%s", csXML.c_str());
return 0;
}
결과는 다음과 같습니다.
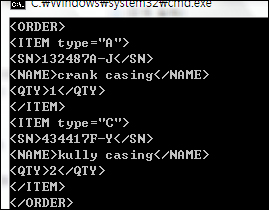
AddElement를 통해 엘리먼트를 만들고, 해당 엘리먼트의 자식을 추가하기 위해 AddChildElem을 사용하거나 먼저 IntoElem을 호출한 후 다시 AddElement를 사용합니다.
이제 반대로 위와 같은 XML 데이터를 읽어 보도록 하겠습니다. 먼저 위의 결과를 파일로 저장해 놓고 그 파일을 읽어 데이터를 추출하는 예제를 들어 보겠습니다. 예를 들어… 아이템(ITEM)의 이름(NAME)과 수량(QTY)을 읽어 보도록 하겠습니다. 위의 XML 문자열의 경우 아이템의 개수는 총2개이므로 2개가 검색될 것입니다. 다음이 이 예제와 부합되는 코드입니다.
CMarkup xml;
xml.Load("d:/data.xml");
while ( xml.FindChildElem("ITEM") )
{
xml.IntoElem();
xml.FindChildElem( "NAME" );
std::string csSN = xml.GetChildData();
xml.FindChildElem( "QTY" );
int nQty = atoi(xml.GetChildData().c_str());
xml.OutOfElem();
printf("%s, %d\n", csSN.c_str(), nQty);
}
먼저 XML 데이터를 가지고 있는 파일을 Load 매서드를 이용해 읽습니다. 다시 반복문을 사용하여 루트 엘리먼트의 자식 ITEM 엘리먼트를 검색하기 위해 FindChildElem을 사용합니다. 그러면 해당되는 자식 엘리먼트가 추출됩니다. 해당되는 자식 엘리먼트의 자식 엘리먼트를 읽기 위해 IntoElem() 함수를 사용한 뒤에 원하는 엘리먼트(NAME, QTY)를 검색하기 위해 FindChildElem을 호출하고 실제로 값을 읽기 위해서 GetChildData 매서드를 호출합니다. 다 읽은 후 OutOfElem()을 호출합니다. 결과는 아래와 같습니다.
![]()