수집된 데이터를 활용하여 AI 학습하기에 앞서 가장 먼저 해야 할 것은 수집된 데이터를 개략적으로 살펴보는 일입니다. 이 글은 간단하지만 의미있는 데이터셋을 개략적으로 살펴보는 것에 대한 내용을 살펴봅니다.
간단하지만 의미있는 데이터셋은 Kaggle에서 제공하는 전복(Abalone) 데이터셋이며 다운로드 받은 파일은 CSV 형식으로 파일을 열어 그 일부를 보면 다음과 같습니다.
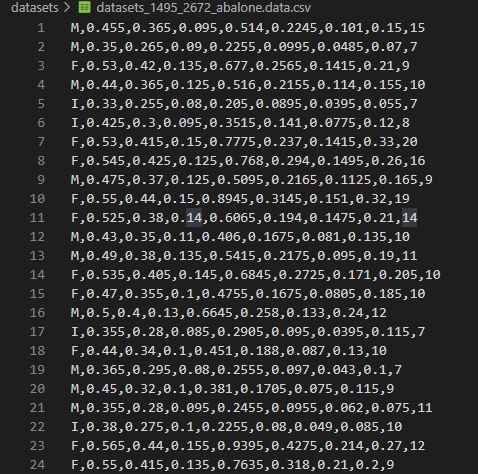
내용을 보면 일반적인 첫줄에 컬럼명이 아닌 바로 데이터값으로 시작하는 것과 총 9가지의 컬럼값으로 구성되어 있다는 것을 파악할 수 있습니다.
이제 이 데이터를 파이선을 통해 개략적으로 살펴보도록 하겠습니다.
pandas를 사용하여 파일을 불러오는 코드로 시작합니다.
import pandas as pd
raw_data = pd.read_csv('./datasets/datasets_1495_2672_abalone.data.csv',
names=['sex', 'tall', 'radius', 'height', 'weg1', 'weg2', 'weg3', 'weg4', 'ring_cnt'])
데이터에 컬럼 정보가 없으므로 names 인자를 통해 컬럼의 의미를 파악할 수 있으면서 식별자로 사용할 수 있는 이름을 지정해 줍니다. 총 9개인데, 각각의 의미는 ‘성별’, ‘키’, ‘지름’, ‘높이’, ‘전체무게’, ‘몸통무게’, ‘내장무게’, ‘껍질무게’, ‘껍질의고리수’입니다.
개략적인 내용 파익으로 이 데이터셋의 실제 내용 중 시작부분을 살펴보는 코드입니다.
print(raw_data.head())
결과는 다음과 같습니다.

다음은 전체적인 데이터의 구성을 살펴보는 코드입니다.
print(raw_data.info())
결과는 다음과 같은데, 총 4177개의 전복 데이터가 있으며 각 컬럼 데이터의 타입과 Null 값이 아닌 데이터의 개수 정보를 파악할 수 있습니다. sex 컬럼의 데이터 타입은 object인데, 이는 문자열이기 때문입니다.

앞서 sex가 문자열인데, 이는 전복의 성별값입니다. I는 유충, M은 수컷, F는 암컷인데, 이 sex에 대한 정보를 좀더 살펴보기 위한 코드입니다.
print(raw_data['sex'].value_counts())
결과는 다음과 같은데, 수컷(M)이 1528개, I가 1342개, F가 1307라는 것을 알 수 있습니다.

다음은 데이터에 대한 간단한 통계를 확인하기 위한 코드입니다.
print(raw_data.describe())
결과는 다음과 같습니다.

각 컬럼에 대한 데이터수, 평균, 편차, 최대값, 최소값, 25%/50%/75%에 대한 백분위수(Percentile)가 제공됩니다.
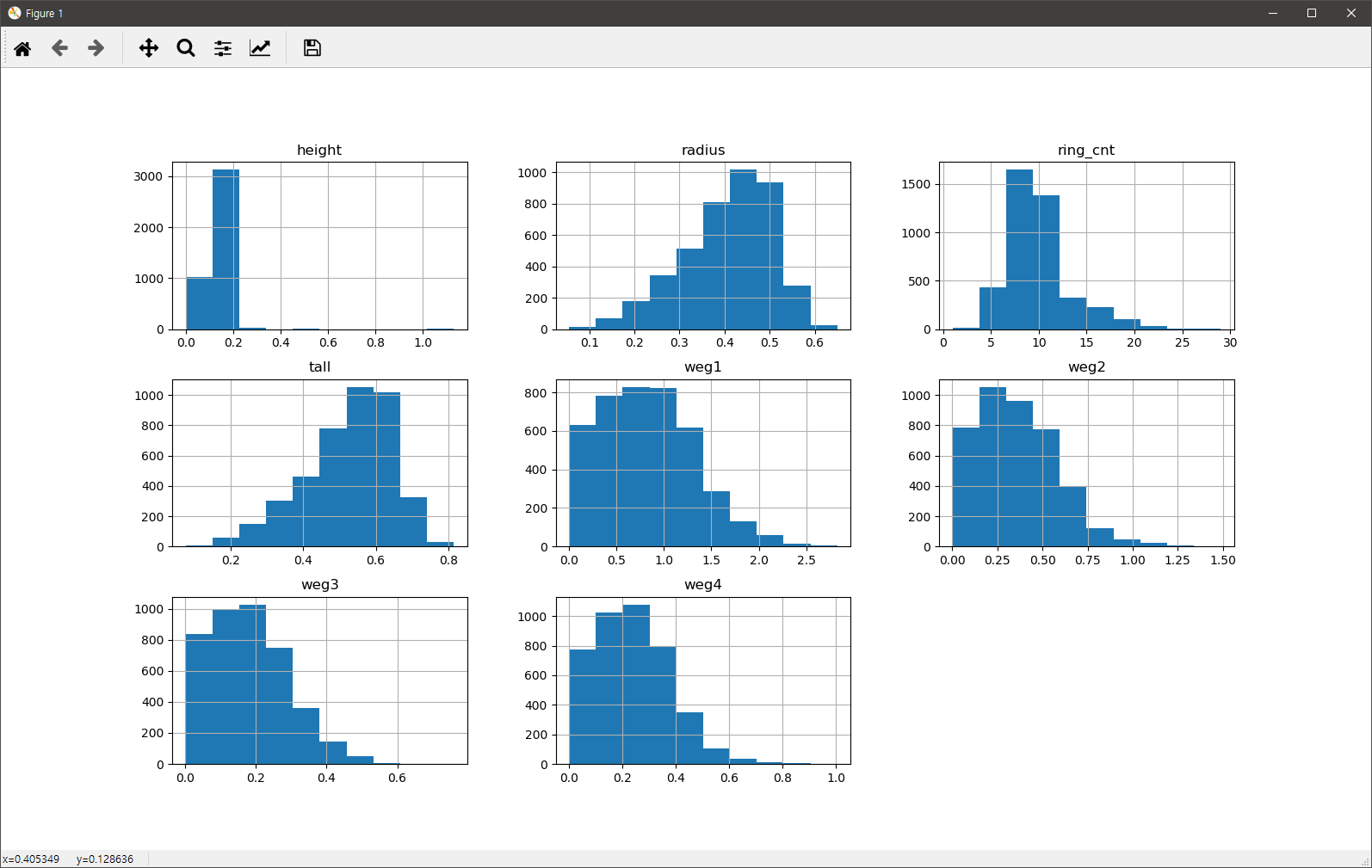
끝으로 각 컬럼에 대한 히스토그램을 살펴보는 코드입니다.
import matplotlib.pyplot as plt raw_data.hist(bins=10) plt.show()
결과는 다음과 같습니다.