
최단 경로 탐색 알고리즘 중 A*(A Star, 에이 스타) 알고리즘에 대해 실제 예시를 통해 풀어가면서 설명하겠습니다. A* 알고리즘은 시작 노드만을 지정해 다른 모든 노드에 대한 최단 경로를 파악하는 다익스트라 알고리즘과 다르게 시작 노드와 목적지 노드를 분명하게 지정해 이 두 노드 간의 최단 경로를 파악할 수 있습니다.
A* 알고리즘은 휴리스틱 추정값을 통해 알고리즘을 개선할 수 있는데요. 이러한 휴리스틱 추정값을 어떤 방식으로 제공하느냐에 따라 얼마나 빨리 최단 경로를 파악할 수 있느냐가 결정됩니다.
A*에 대한 서론은 최대한 배제하고 하나의 명확한 예를 통해 풀어나가며 설명하도록 하겠습니다. 다음과 같은 예를 통해 먼저 살펴보겠습니다.
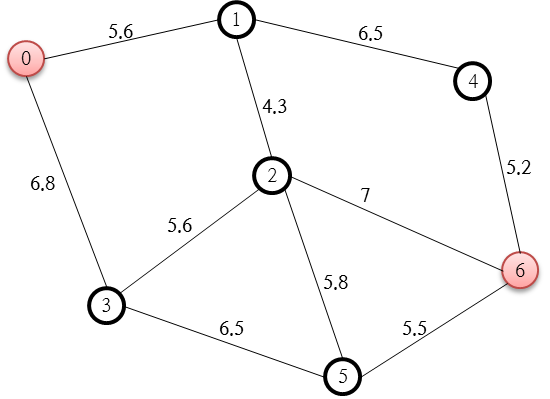
위의 예는 시작점인 0번 노드에서 목적지인 6번 노드로 가는 최단 경로를 A* 알고리즘으로 분석하고자 하는 것인데요. 각 노드 사이에 연결된 링크에 붙은 숫자는 노드 사이를 이동하는데 소요되는 비용(경비, Cost)입니다. 위의 경우 거리값입니다. 즉, 노드 사이의 거리가 길수록 비용이 늘어나므로 비용값으로써 합리적입니다.
A* 알고리즘을 통한 위의 문제 해결을 위해 가장 먼저 수행하는 첫 과정은 다음과 같습니다.
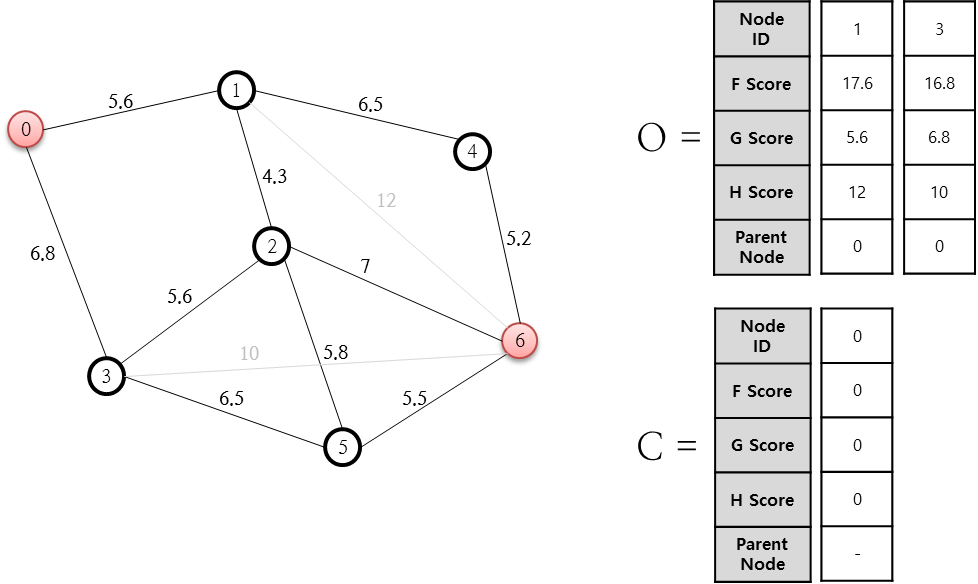
위의 그림에서 보면 저장소로 O와 C가 있는데요. O는 열린 목록(Open List), C는 닫힌 목록(Close List)인데요. 열린 목록인 O 저장소에는 최단 경로를 분석하기 위한 상태값들이 계속 갱신되며, C 저장소는 처리가 완료된 노드를 담아 두기 위한 목적으로 사용됩니다. 이러한 O와 C의 저장소를 기반으로 0번 노드에서 6번 노드까지의 최단 경로를 산출해 보도록 하겠습니다.
먼저 출발 노드인 0을 닫힌 목록인 C 목록에 집어 넣습니다. 그리고 이 0번 노드와 연결된 노드는 1번과 3번 노드를 열린 목록인 O 저장소에 추가합니다. 추가할 때 F, G, H, Parent Node값도 함게 추가해야 하는데요. 먼저 F = G + H입니다. G는 시작 노드에서 해당 노드까지의 실제 소요 경비값이고, H는 휴리스틱 추정값으로 해당 노드에서 최종 목적지까지 도달하는데 소요될 것이라고 추정되는 값입니다. Parent Node는 해당 노드에 도달하기 직전에 거치는 노드 번호입니다. 먼저 1번 노드에 대한 F, G, H, Parent Node를 살펴 보겠습니다. 출발점인 0번 노드로부터 시작했으므로, 1번 노드의 Parent Node는 0번 노드입니다. 그리고 G 값은 0번 노드에서 1번 노드까지의 거리 비용값인 5.6입니다. H 값을 추정하기 위한 기준이 필요한데요. 이 추정값에 대한 기준을 1번 노드에서 목적지인 6번 노드까지의 직선 거리로 하기로 정하고 측정을 하니(줄자로 재든, 좌표가 있다면 피타고라스 정리를 통해 두 좌표 사이의 거리를 계산하든 하여 얻을 수 있음) 12로 산출되므로 H는 12가 됩니다. F = G + H이므로 5.6 + 12인 17.6이 됩니다. 3번에 대한 F, G, H, Parent Node 역시 이와 동일하게 결정할 수 있습니다. 여기서 다음 단계로 진행합니다.
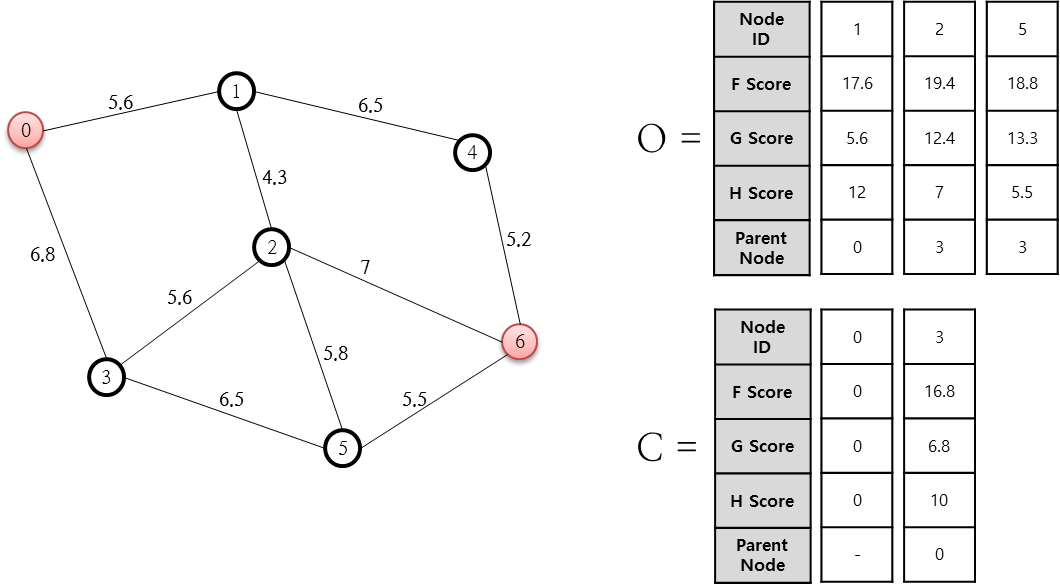
O 리스트 중 F 값이 가장 작은 노드는 3번인데요. 이 노드 3번을 C 리스트에 추가하고 3번 노드와 연결된 0, 2, 5 중 닫힌 목록에 존재하지 않는 2, 5번 노드에 대해 열린 목록에 추가합니다. 2, 5에 대한 F, G, H, Parent Node를 계산해 기록합니다. 먼저 2번 노드에 대해 계산해 보면.. 2번 노드에 대한 G 값은 바로 직전 노드에 소요되는 비용(6.8)에 3번 노드에서 2번 노드까지 도달하기 위한 비용인 5.6을 합한 값인 12.4가 됩니다. 그리고 H 값은 2번 노드에서 목적지은 6번까지에 대한 거리값인 7이 됩니다. 5번 노드에 대한 것도 이와 동일하게 계산합니다. 다음으로 진행합니다.
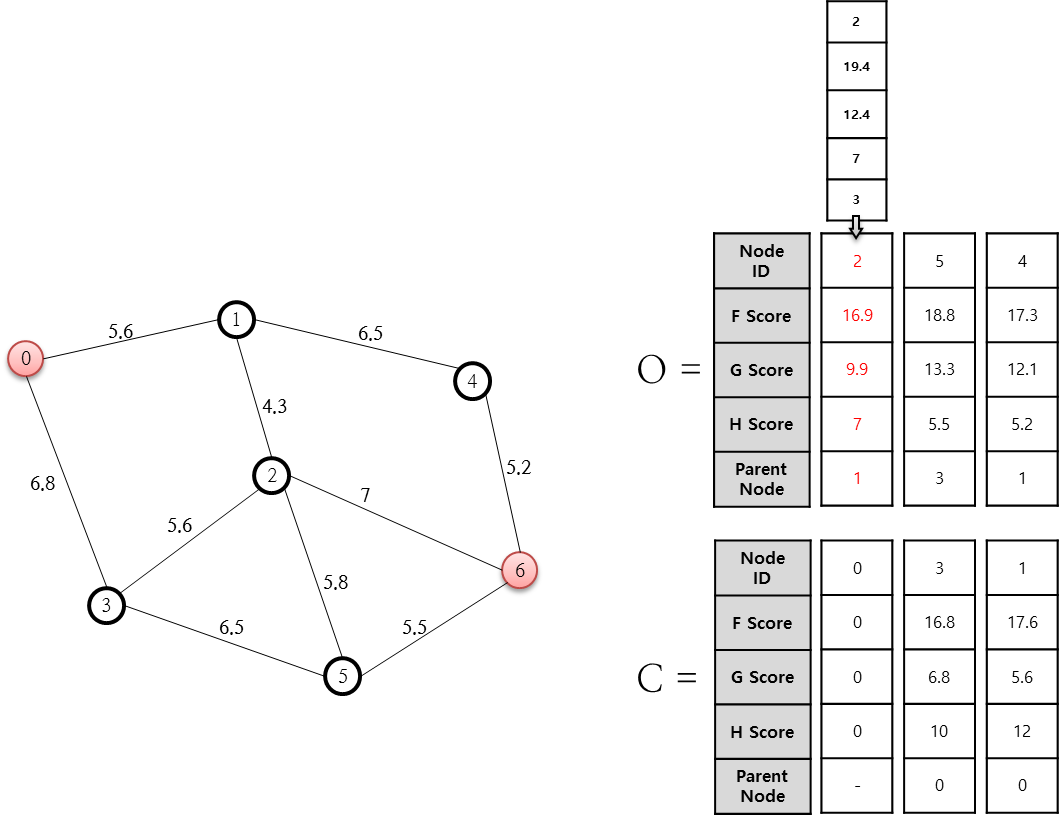
열린 목록(O 저장소) 중 F 값이 가장 작은(최소인) 1번 노드를 닫힌 목록에 추가합니다. 그리고 이 1번 노드와 연결된 2, 4번 노드 중 닫힌 목록(C 저장소)에 존재하지 않는 것에 대해 다시 F, G, H, Parent Node를 계산합니다. 이 상태에서 4번 노드는 열린 목록에 없었던 것이기에 그냥 F, G, H, Parent Node를 이미 앞서 설명했던 방식으로 계산해 추가하면 그만이지만 2번 노드는 전 단계에서 이미 추가되어 있었는데요. 이렇게 전 단계에서 추가된 G 값이 새롭게 계산된 G 값보다 크다면 새롭게 계산된 F, G, H, Parent Node 값으로 변경해 줘야 하며 위의 그림이 이러한 변경을 나타내고 있습니다. 다음 단계로 진행합니다.
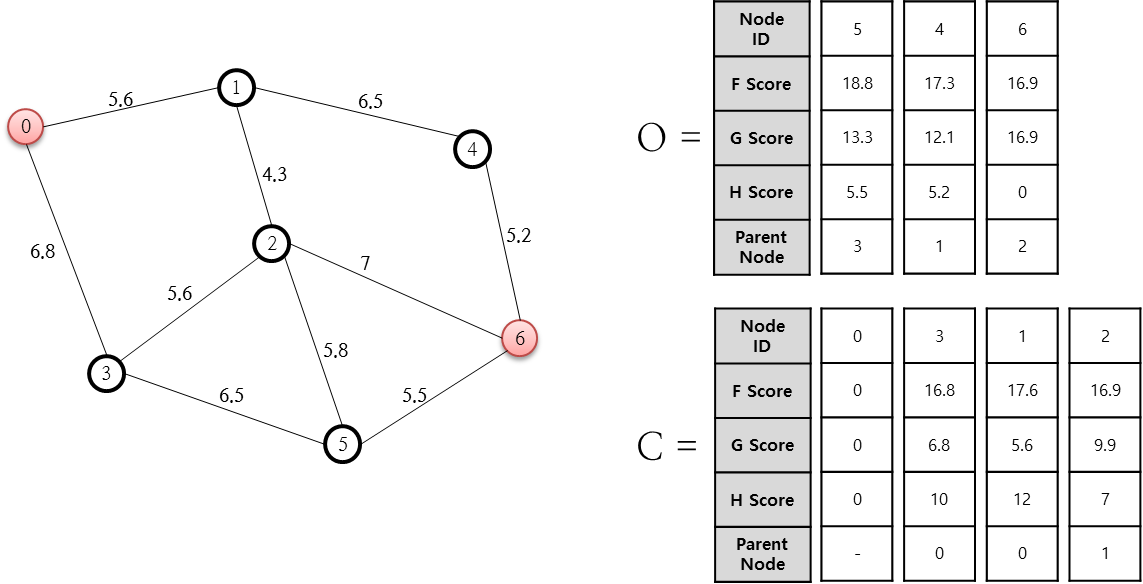
열린 목록 중 F가 최소인 노드는 2번 노드이고, 이 2번 노드를 닫힌 목록에 추가합니다. 그리고 2번 노드와 연결된 1, 3, 5, 6번 노드 중 닫힌 목록에 존재하지 않는 5, 6번 노드에 대한 F, G, H Parent Node 값을 계산합니다. 5번 노드의 경우 새로운 G 값이 기존 값보다 크므로 변경하지 않고 6번 노드에 대한 값들만을 계산해 추가합니다. 다음 단계로 진행합니다.
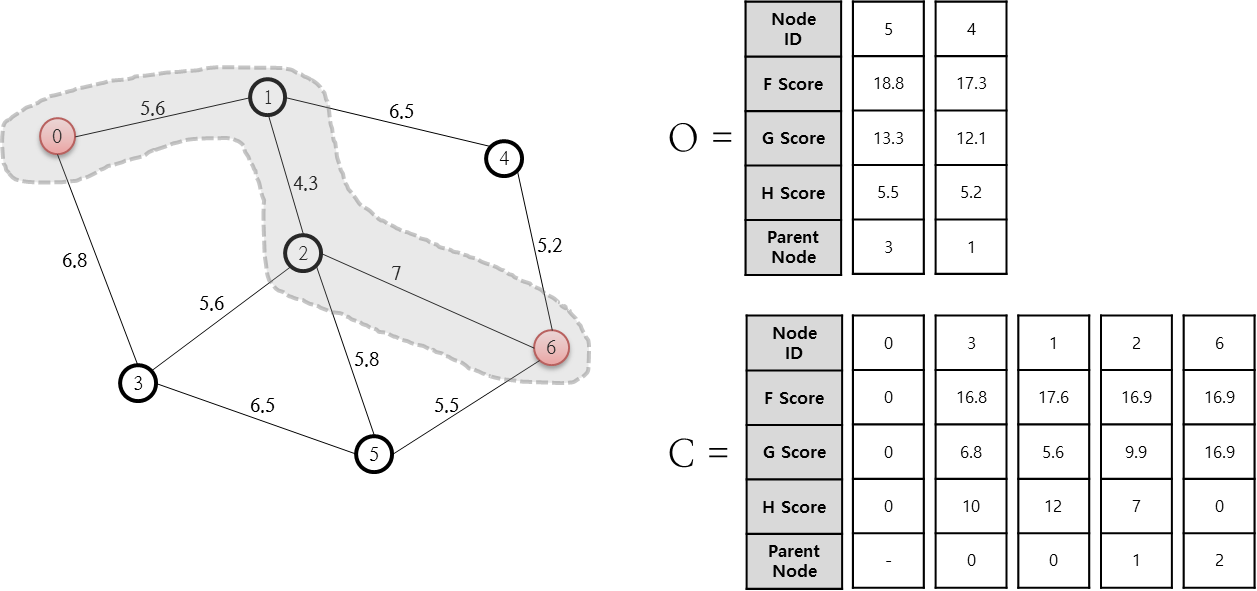
열린 목록 중 F가 최소인 노드는 6번 노드인데요. 이 6번 노드를 닫힌 목록에 추가합니다. 그런데 이 6번 노드는 최종 목적지 노드이므로 A* 알고리즘은 종료됩니다.
여기까지 만들어진 닫힌 목록(C 저장소)를 토대로 0번 노드에서 6번 노드까지의 최단 경로를 파악할 수 있습니다. 6번 노드의 Parent Node는 2번 이고, 2번 노드의 Parent Node는 1번이며, 1번 노드의 Parent Node는 0번이므로 최단 경로는 6번 노드←2번 노드←1번 노드←0번 노드가 됩니다.
A* 알고리즘 설명을 하는 포스팅들은 대부분 번역 문이거나 서술어와 목적어를 제대로 구분하지 않고 일기쓰듯이 나열한 포스팅들인데 (그래서 정확하게 이해하기 힘든 것이 대부분이더군요.)
이 포스팅은 설명도 깔끔하고 개발에 바로 적용해 볼 수 있는 가장 적절한 포스팅인 것 같습니다.
큰 도움 되었습니다.
감사합니다.
좋은 말씀 감사합니다 !
Parent node 부분이 이해가 잘 안됬는데 덕분에 쉽게 알아갑니다
안녕하세요, 김형준입니다.
도움이 되셨다니~ 참 좋습니다.
관련내용 공부하던 중 도움이 많이 되었습니다. 공부하는 내용을 블로그에 정리하고 있는데 출처를 남기고 참고해서 작성해도 괜찮을까요?
안녕하세요, 김형준입니다.
원문을 그대로 Copy&Paste가 아니라면 괜찬습니다.
출처는 꼭 남겨주시구요~
안녕하세요 글 잘 봤습니다.
글을 너무 잘쓰셔서 이해가 잘 됬습니다만, 마지막에서 6번노드(종점)로부터 시작노드(0)까지 다시 역추적은 어떻게 진행하나요?
역추적이되어야 전체경로(0-1-2-6 )를 알 수 있으니까요.
아 그리고 한가지만 더 질문하고싶은데, 휴리스틱값을 구하는 과정에서 피타고라스정리를쓰든 줄자로 재든 구하라고하셧는데 지금 저기서는 각도도안주어져있고 변들끼리의 비율도안주어져있는데 어떻게 구하신건가요?
안녕하세요, 김형준입니다.
이 글에서는 두 지점간의 단순 거리를 휴리스틱값으로 했습니다.
거리도 거리지만, 저는 구현중에 방향도 휴리스틱값으로 고려해 볼만 하다라는 생각을 했었습니다.
그럼 참고하시기 바랍니다.
안녕하세요.
휴리스틱값을 사용하셧다고했는데 어떤통계를 근거로 하신건가요?
혹시 그냥 감으로적으신건가요?
3번노드와 6번노드의 직선거리인 10을 코사인2법칙으로 풀어보니까 9.5가 나오더라구요
안녕하세요~ 김형준입니다.
제가 사용한 휴리스틱값은 계산 대상이 되는 두 노드간의 직선거리입니다.
가장 쉽게 생각해서 직선거리가 가까운 것을 우선순위를 더 두어 계산하는 것이 나을 것이라는 것에서 출발한것입니다.
네 그럼 구체적으로 어떻게 계산하신거에요?
안녕하세요, 김형준입니다. 두 지점간의 거리는 sqrt(pow(x1-x2,2)+pow(y1-y2)) 로 계산한 것입니다. 근데 이걸 물어 보시는 거 같진 않은데요.. 정확히 무엇을 물어보시는것인지요?
그거 물어본거 맞습니다. 직선거리 구체적으로 어떤수식으로 구했는지…
근데 x,y좌표는 어디있나요? 저그림에서.
네..
닫힌 목록(C)의 마지막 6번 노드가 최종 목적지라는 것은 이미 아실테구요..
닫힌 목록의 6번 노드의 Parent Node 값을 활용해 역으로 추적할 수 있답니다.
아 부모노드를 깜빡햇네요 감사합니다
이미 닫힌목록(C저장소)에
6의 Parent Node = 2
2 의 P-Node = 1
1 의 P-Node =0
이라고 저장되어 있네요
저도 처음에 C저장소에 3이 있으니 0-3-2-6 결과가 나오지 않을까 봤더니
6부터 시작하면 3이 C저장소에 있어도 관계가 없네요
아.. 혹시 내용이 잘못되었다는 말씀이신가요?
포스팅 잘 봤습니다. 혹시 그래프는 어떤 프로그램으로 그리셨는지 알 수 있까요??
안녕하세요, 김형준입니다.
PowerPoint로 그렸답니다.
감사합니다!
Wow 위키보고 부족해서 A*찾고 있었는데 설명해주신거 보고 많은 도움이 됐고 이론으로만 접하던 너비우선탐색이 머릿속에 그려지네요 감사합니다. ㅎ
스스로 프로그래밍을 배운지 얼마 안되어 물어볼 사람도 없고 이해하기 어려웠는데 좋은 설명 빠르게 이해되었습니다. 감사합니다.
설명 너무 좋습니다. 감사합니다.
설명감사합니다. A*가 정말 쉽게 이해되었습니다.
혹시 한가지 여쭤봐도 될까요?
A*알고리즘을 선생님의 예시 그래프처럼 그래프 자체로 구현할 수 있을까요?
인터넷 예제들은 맵을 구성하게 되어있어서 적용이 힘듭니다ㅜㅜ
안녕하세요, 김형준입니다.
네트워크 데이터에 대한 자료구조는 Graph 구조가 맞지만..
A* 알고리즘의 구현에 있어 OpenList와 CloseList를 구현할때, 그 속도를 위해서는 HashMap 자료구조가 효율적입니다.
참고하시기 바랍니다.
좋은 정보감사합니다!! 많은도윰이되었습니다
수업자료로 쓰려구하는데 괜찮을까요?
안녕하세요, 김형준입니다.
수업 자료르 사용시 출처만 언급하신다면 아무런 문제가 없습니다. ^^
설명잘하셨네요 짱짱 멋집니다.
이해했어요~~ 블로그에 출처 밝히고
나름대로 정리해서 올리겠습니다.~~
안녕하세요, 김형준입니다.
네~ 감사합니다~ ^^
간단한 예제로 모든 케이스에 대해 다 설명이 쉽게 되어있는 것 같아요. 아주 많은 도움이 되었습니다. 감사합니다.
속도를 위해서 hashmap 자료구조가 효율적이라고 했는데 왜 그런지 이유를 알 수 있을가요??
제 생각에는 list사용해도 속도 차이가 안날거 같은데…OPenList, CloseList에서 특정값을 탐색할게 있나요??
알고리즘의 특성 상 NodeID를 key로 하여 검색을 자주 하니.. Key-Value 자료 구조인 HashMap의 자료 구조를 사용한 것입니다. 만약 ArrayList나 LinkedList를 사용했다면 처음부터 순차검색으로 검색해야 할테고.. 속도면에서 느리겠죠..
typedef struct NodeInfo
{
int nodeNum_;
float totalWeight_;
float weight_;
float curWeight_;
float estimatedWeight_;
int prevNodeNum_;
NodeInfo()
:nodeNum_(0), totalWeight_(0.f), weight_(0.f), curWeight_(0.f),
estimatedWeight_(0.f), prevNodeNum_(0) {}
NodeInfo(int nodeNum, float weight, float estimatedWeight)
:nodeNum_(nodeNum), weight_(weight), estimatedWeight_(estimatedWeight),
curWeight_(0.f), totalWeight_(0.f), prevNodeNum_(0) {}
void operator = (NodeInfo nodeInfo)
{
nodeNum_ = nodeInfo.nodeNum_;
totalWeight_ = nodeInfo.totalWeight_;
weight_ = nodeInfo.weight_;
curWeight_ = nodeInfo.curWeight_;
estimatedWeight_ = nodeInfo.estimatedWeight_;
prevNodeNum_ = nodeInfo.prevNodeNum_;
}
}NODEINFO;
class Graph
{
public:
Graph(int nodeNum)
{
graph_.assign(nodeNum, vector());
visitCount_.assign(nodeNum, 0);
}
void AddNode(int startNode, int endNode, float weight, float estimatedweight)
{
graph_[startNode].push_back(NodeInfo(endNode, weight, estimatedweight));
}
void AStar(int startNode, int goalNode)
{
NodeInfo nodeInfo;
nodeInfo.nodeNum_ = startNode;
visitCount_[startNode]++;
while (true)
{
closeList_.push_back(nodeInfo);
if (closeList_.back().nodeNum_ == goalNode)
break;
for (size_t i = 0; i 1)
{
elem.curWeight_ = nodeInfo.weight_ + elem.weight_;
elem.totalWeight_ = elem.curWeight_ + elem.estimatedWeight_;
elem.prevNodeNum_ = nodeInfo.nodeNum_;
visitCount_[elem.nodeNum_]–;
}
if (count == 0 || min.totalWeight_ > elem.totalWeight_)
min = elem;
count++;
}
for (auto iter_begin = openList_.begin(); iter_begin != openList_.end(); ++iter_begin)
{
if ((*iter_begin).nodeNum_ == min.nodeNum_)
{
openList_.erase(iter_begin);
break;
}
}
nodeInfo = min;
}
}
void print()
{
for (auto elem : closeList_)
cout << elem.nodeNum_ << " " << endl;
}
private:
vector<vector> graph_;
list openList_;
list closeList_;
vector visitCount_;
};
a*원리만 보고 제 생각대로 짠 코드입니다. 일단 여기 그래프의 노드들을 넣었을 때 결과가 잘 나왔습니다. 경우가 1개라서 정확한지 모르겠지만… 혹시 수정해야할 부분이 있는지 궁금합니다.
그리고 NodeID를 키값으로 탐색해야 할 경우가 있긴있었습니다. 이 사이트에서는 F, G, H변수가 필요한데 저는 거기에 해당 노드까지의 가중치값을 담을 수 있는 변수를 선언하여 그래프에서 탐색하지 않도록 했습니다. 그리고 해당 노드들의 방문 카운트로 중복해서 openlist에 넣지않도록하며 카운트가 2이상이면 해당 노드의 정보들을 갱신시켰습니다.
우왕 G부분 비교하는거 어떻게되는지 이해가안됐었는데
감사합닏니다 깔끔하네요!
깔끔한 포스팅 감사해요
인공지능과목 탐색 알고리즘을 공부하던 도중에 많은 도움되었습니다.
형님 진짜 너무 감사합니다~
이거 이해할라고 여러 사이트 뒤져보고 별의 별짓을 다 해봤는데 다 f=g+h임 ㅎㅎ 이해 모탐?!
이래서 정말 화가 났었는데요
님 글 보고 다 이해됐어요.
근데요 h값을 추상적으로 구하는거면 구하는 사람이나 프로그램마다 다 다른 값을 도출하지 않을까요???
저 그림에서도 1번에서 6번까지 거리가 대강 12라고 하셨는데 이해가 안되는게요 삼격형이 성립하려면 가장 긴 변이 나머지 두 변의 합보다 작아야 되는데 처음이 휴리스틱 추정값 구할 때 1번노드랑 2번 노드 이은거 + 2번노드 랑 6번노드 이은거<1번노드랑 6번노드 이은거(h값)가 되는데 오류 아닌가요?! 아님 말고요 ㅎ
안녕하세요, 김형준입니다.
h값은 휴리스틱값으로, 의미 그대로 경험값입니다.
즉, 개발자마다 자신의 경험치를 토대로 다양한 값으로 지정해도 됩니다.
물론, 그 의미와 목적에 맞게 지정되어야겠지만요.
잘 보고 갑니다. 인공지능 수업 과제를 위해 찾던중… 아주 설명이 잘 되어 있어서~ 이해가 뽝뽝 되네요~
좋은 포스팅 감사합니다! 이해가 잘 되었어요.
안녕하세요 김형준님!
덕분에 알고리즘을 제대로 이해할 수 있었습니다.
제가 요즘 알고리즘 공부 후 블로그에 글을 작성하면서 내용을 정리하고 있는데
혹시 실례가 안된다면 위 예제를 바탕으로 간단한 설명과 코드를 블로그에 포스팅해도 괜찮을까요?
안녕하세요. 김형준님!
덕분에 알고리즘 이해를 제대로 할 수 있었습니다.
제가 배운 알고리즘을 블로그에 정리해가며 공부하고 있는데
실례가 안된다면 위 예제를 바탕으로 간단한 설명이랑 코드를 작성해서 포스팅해도 괜찮을까요??
안녕하세요, 김형준입니다.
네, 출처만 언급해주신다면 괜찬습니다..
가중치가 음수일 경우에도 알고리즘이 작동하는건가요?
추가로 단일 출발지와 최종 목적지가 존재하며 중간의 경유지를 모두 거치는 최적 경로를 도출하려면 어떤 알고리즘을 써야될지 여쭤봐도 될까요?
상기 알고리즘은 모든 경로를 거치지 않아도 최종 목적지까지 최소 비용이 되면 경로가 확정되는 듯하여 문의 드립니다.
A* 알고리즘은 사용자가 지정한 출발점과 종료점을 구성하는 경로 중 가장 최적의 경로를 산출합니다.
이를 이용한다면 경유지를 고려한 A* 알고리즘도 유의미하게 활용될 수 있으리라 생각됩니다.
단순하게는 출발점과 경유지들 그리고 목적지에 대한 모든 출발과 종료점에 대한 경로를 산출하고 정렬하는 방식이 가능하겠고…..
각 출발점과 종료점의 산출 과정 중 중간에 산출해야할 목적지가 나온다면 이를 활용해 좀더 효율적으로 정렬할 수도 있겠죠..
누군가 만들어 둔 새로운 알고리즘을 찾기보다… 기본되는 알고리즘을 이해하고 있다면.. 이를 통한 스스로의 확장이 더 재미있을거 같단 생각이 듭니다.
안녕하세요. 1번 노드에서 휴리스틱 값을 측정하실 때 직선거리 값인 12로 놓으셨는데, 오류가 있는 것 같아요. 삼각형 결정조건이 ‘가장 긴 변이 다른 두 변의 합보다 작다’ 인데, 7+4.3=11.3으로 가장 긴 변인 12의 크기를 넘지 못합니다. 6.5+5.2=11.7도 마찬가지고요. 11이나 혹은 그 이하의 값으로 측정해야 되는 게 아닐까요/
안녕하세요, 김형준입니다.
희한한 삼각형이라고 생각하시면 됩니다.
A*알고리즘 작동원리를 까먹어서 찾고 있었는데 딱이네요ㅎㅎ 감사합니다.
이거 보고 한 번에 이해했습니다. 감사합니다.
댓글 감사합니다^^
업무 중에 A스타 알고리즘을 알아야 했는데 쉽게 이해가 되었습니다!
댓글 감사~! 도움이 되셨다니 다행입니다.
덕분에 잘 이해했습니다 감사합니다
여러 번 다시 공부한 개념 덕분에 확실히 이해했습니다. 감사합니다!
안녕하세요. 좋은 자료 정말 감사합니다… 논문에 참고 자료로 쓰려고 하는데 괜찮을까요? 물론 작성자와 출처는 명시할 건데요..! 부탁드립니다..
네..
좋은 글 감사합니다!! 지금까지 봤던 A* 알고리즘 정리 글 중에서 가장 직관적이고 깔끔한 설명인 듯합니다 ㅠ 덕분에 A* 알고리즘을 조금 더 이해하게 되었습니다.
안녕하세요~ 댓글 감사합니다~ ^^
좋은 자료 감사합니다.
하나 궁금한 점이 있는데요.
이전에 open list 에 있던 노드가 한번 더 주변 노드로 인식되었을대
해당 노드의 이전 gscore 값이랑 현재 gscore 값을 비교해서 더 작은 값으로 변경해준다고 하셨는데
그냥 gscore 값이 더 작은 시기의 f, g, h 값으로 바꾸는 건가요
아니면 두 경우의 fscore 까지 계산해서 fscore 가 더 작은 시기의 값으로 바꾸는 건가요??
이 부분이 궁금합니다.