
하나의 필드에 여러 개의 값을 저장해야 할 때 Array 타입을 사용하면 매우 유용합니다. 이 글은 PostgreSQL에서 Array 타입에 대한 내용을 정리합니다.
먼저 Array 타입을 가지는 테이블을 생성합니다.
CREATE TABLE contacts ( id serial PRIMARY KEY, name VARCHAR (100), phones TEXT[] );
이 테이블에 한개의 Row를 추가하는 SQL문의 예는 다음과 같습니다.
INSERT INTO contacts (name, phones)
VALUES('홍길동', ARRAY [ '031-132-7890','02-678-9876' ]);
한번에 여러 개의 Row를 추가하는 SQL문은 다음 예와 같습니다.
INSERT INTO contacts (name, phones)
VALUES
('일지매', ARRAY [ '02-789-5432' ]),
('김갑환', '{"010-4567-8765", "063-123-1234"}'),
('김형준', '{"063-432-8765", "010-4567-8765"}');
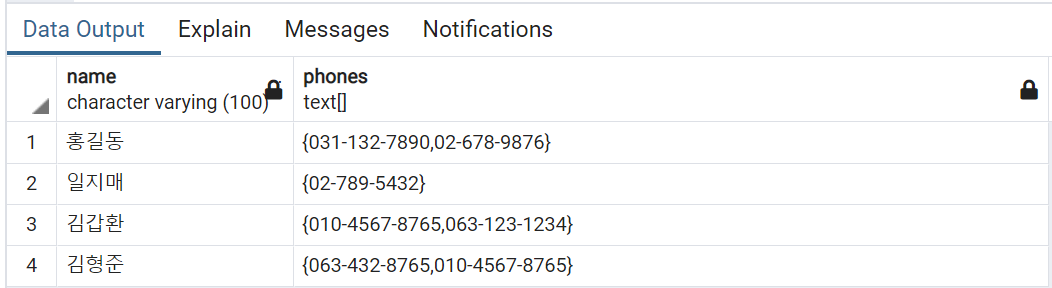
테이블의 데이터를 확인해 보기 위해 다음 SQL를 실행해 봅니다.
SELECT name, phones FROM contacts;
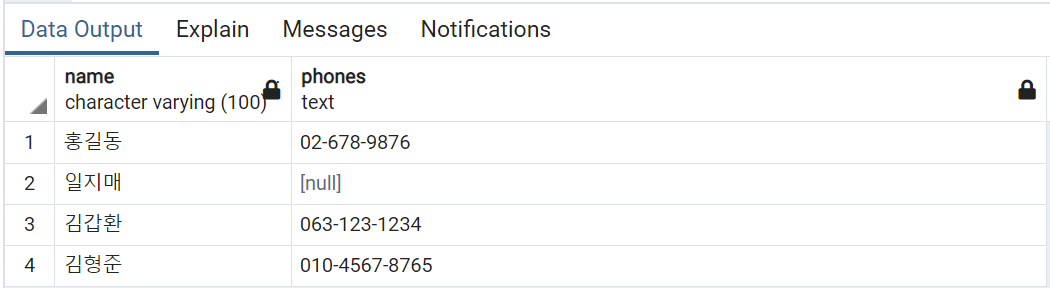
배열의 특정 인덱스를 지정해서 조회를 할 수도 있습니다. 다음처럼 배열의 2번째 값만을 조회합니다.
SELECT name, phones[2] FROM contacts;
결과는 다음과 같습니다.
다음은 배열의 값 중 2번째에 대해 특정값과 일치하는 내용을 조회하는 SQL 문입니다.
SELECT name, phones FROM contacts WHERE phones[2] = '010-4567-8765';
결과는 다음과 같습니다.

다음은 배열을 구성하는 모든 값 중 특정값과 일치하는 내용을 조회하는 SQL 문입니다.
SELECT name, phones FROM contacts WHERE '010-4567-8765' = ANY(phones);
결과는 다음과 같습니다.

그렇다면 배열을 구성하는 모든 값 중 부분적으로 일치하는 LIKE 구문을 사용해 본다면 다음 SQL처럼 구성될 것입니다. (작동하지 않음)
SELECT name, phones FROM contacts WHERE ANY(phones) LIKE '%32%';
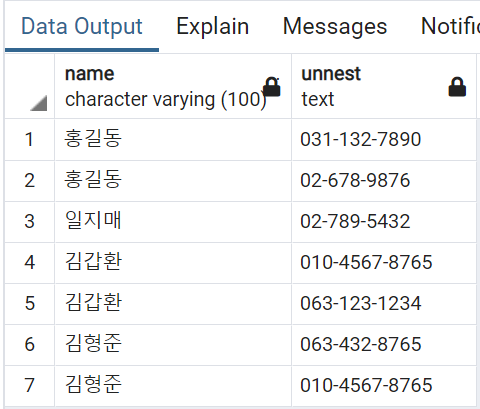
작동하지 않는데요. 이는 다음에 설명할 UNNEST 명령을 사용해야 합니다. UNNEST는 배열을 구성하는 값들을 독립시켜 하나의 Row로 구성해 줍니다. 다음 SQL 문을 통해 결과를 보시면 이해가 쉬울것입니다.
SELECT name, UNNEST(phones) FROM contacts;
결과는 다음과 같습니다.
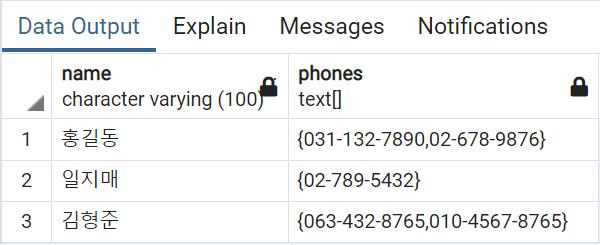
이제 앞서 문제가 된 LIKE 구문을 UNNEST를 사용하면 다음과 같습니다.
SELECT name, phones
FROM (
SELECT name, UNNEST(phones) phone, phones
FROM contacts) x
WHERE phone LIKE '%32%';
결과는 다음과 같습니다.
배열 값 중 특정 순서의 값 만을 변경할 수도 있습니다.
UPDATE contacts SET phones[4] = '010-9999-9999' WHERE name = '김갑환';
SQL문으로 name이 ‘김갑환’인 것만 조회해 보면 다음과 같습니다.

보시면 원래의 배열의 구성 값의 개수가 2개였는데 4번째에 값을 추가하여 3번째는 NULL로 지정된 것을 확인할 수 있습니다.
마지막으로 Array 타입의 필드에 대한 Index를 거는 구문은 다음과 같습니다.
CREATE INDEX idx_phones on contacts USING GIN (phones);