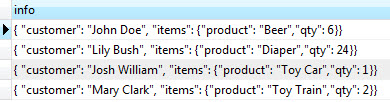
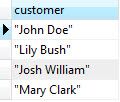
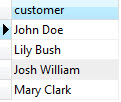
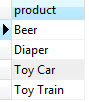
어떤 지점(p)에서 Ray(r)에 가장 가까운 r 위의 좌표 얻기
struct ray {
vec3 o, d;
};
vec3 ClosestPoint(ray r, vec3 p) {
return r.o + max(0., dot(p-r.o, r.d)) * r.d;
}
위의 ClosePoint를 이용하면 ray와 어떤 지점에 대한 최단 거리를 아래 함수를 이용해 구할 수 있다.
float DistRay(ray r, vec3 p) {
return length(p - ClosestPoint(r, p));
}
선 그리기 함수
float line(vec2 p, vec2 a, vec2 b) {
vec2 pa = p - a, ba = b - a;
float t = clamp(dot(pa, ba)/dot(ba, ba), 0., 1.);
vec2 c = a + ba * t;
float d = length(c - p);
return smoothstep(fwidth(d), 0., d - .001);
}
0 ~ 1 사이의 값을 갖는 간단한 노이즈 함수
float random (in vec2 st) {
return fract(sin(dot(st.xy,
vec2(12.9898,78.233)))*
43758.5453123);
}
// Based on Morgan McGuire @morgan3d
// https://www.shadertoy.com/view/4dS3Wd
float noise (in vec2 st) {
vec2 i = floor(st);
vec2 f = fract(st);
// Four corners in 2D of a tile
float a = random(i);
float b = random(i + vec2(1.0, 0.0));
float c = random(i + vec2(0.0, 1.0));
float d = random(i + vec2(1.0, 1.0));
vec2 u = f * f * (3.0 - 2.0 * f);
return mix(a, b, u.x) +
(c - a)* u.y * (1.0 - u.x) +
(d - b) * u.x * u.y;
}
-1 ~ 1 사이의 값을 갖는 Simplex 노이즈 함수
// Some useful functions
vec3 mod289(vec3 x) { return x - floor(x * (1.0 / 289.0)) * 289.0; }
vec2 mod289(vec2 x) { return x - floor(x * (1.0 / 289.0)) * 289.0; }
vec3 permute(vec3 x) { return mod289(((x*34.0)+1.0)*x); }
//
// Description : GLSL 2D simplex noise function
// Author : Ian McEwan, Ashima Arts
// Maintainer : ijm
// Lastmod : 20110822 (ijm)
// License :
// Copyright (C) 2011 Ashima Arts. All rights reserved.
// Distributed under the MIT License. See LICENSE file.
// https://github.com/ashima/webgl-noise
//
float snoise(vec2 v) {
// Precompute values for skewed triangular grid
const vec4 C = vec4(0.211324865405187,
// (3.0-sqrt(3.0))/6.0
0.366025403784439,
// 0.5*(sqrt(3.0)-1.0)
-0.577350269189626,
// -1.0 + 2.0 * C.x
0.024390243902439);
// 1.0 / 41.0
// First corner (x0)
vec2 i = floor(v + dot(v, C.yy));
vec2 x0 = v - i + dot(i, C.xx);
// Other two corners (x1, x2)
vec2 i1 = vec2(0.0);
i1 = (x0.x > x0.y)? vec2(1.0, 0.0):vec2(0.0, 1.0);
vec2 x1 = x0.xy + C.xx - i1;
vec2 x2 = x0.xy + C.zz;
// Do some permutations to avoid
// truncation effects in permutation
i = mod289(i);
vec3 p = permute(
permute( i.y + vec3(0.0, i1.y, 1.0))
+ i.x + vec3(0.0, i1.x, 1.0 ));
vec3 m = max(0.5 - vec3(
dot(x0,x0),
dot(x1,x1),
dot(x2,x2)
), 0.0);
m = m*m ;
m = m*m ;
// Gradients:
// 41 pts uniformly over a line, mapped onto a diamond
// The ring size 17*17 = 289 is close to a multiple
// of 41 (41*7 = 287)
vec3 x = 2.0 * fract(p * C.www) - 1.0;
vec3 h = abs(x) - 0.5;
vec3 ox = floor(x + 0.5);
vec3 a0 = x - ox;
// Normalise gradients implicitly by scaling m
// Approximation of: m *= inversesqrt(a0*a0 + h*h);
m *= 1.79284291400159 - 0.85373472095314 * (a0*a0+h*h);
// Compute final noise value at P
vec3 g = vec3(0.0);
g.x = a0.x * x0.x + h.x * x0.y;
g.yz = a0.yz * vec2(x1.x,x2.x) + h.yz * vec2(x1.y,x2.y);
return 130.0 * dot(m, g);
}
좀더 고른 분포의 랜던 hash
uvec2 murmurHash21(uint src) {
const uint M = 0x5bd1e995u;
uvec2 h = uvec2(1190494759u, 2147483647u);
src *= M;
src ^= src>>24u;
src *= M;
h *= M;
h ^= src;
h ^= h>>13u;
h *= M;
h ^= h>>15u;
return h;
}
// 2 outputs, 1 input
vec2 hash21(float src) {
uvec2 h = murmurHash21(floatBitsToUint(src));
return uintBitsToFloat(h & 0x007fffffu | 0x3f800000u) - 1.0;
}
smoothstep의 보간식
아래의 a와 b는 동일한 값이다.
float f = uv.x; float a = smoothstep(0., 1., f); float b = f * f * (3. - 2. * f);
위의 보간식을 cubic Hermite curve(큐빅 헤르미트 곡선)라고 한다. 0~1 사이의 영역에서 시작과 끝을 좀더 편평하게 만들어주는 quintic interpolation cuver(퀸틱 보간 곡선)에 대한 코드는 다음과 같다.
float f = uv.x; float b = f * f * f * (6. * f * f - 15. * f + 10.);

modelMatrix로 변환된 normal 얻기
varying vec3 vNormal; ... vNormal = mat3(transpose(inverse(modelMatrix))) * normal;
프레그먼트 쉐이더에서는 받은 vNormal을 반드시 정규화(normalize)해야 한다.
3초 주기로 0 ~ 1 사이의 연속된 값 얻기
uniform float u_time; // 0, 1, 2, ...의 값이며 각각 0초, 1초, 2초, ...를 나타냄 ... float period = 3.; // 3초 주기 float t = mod(u_time, period) / period; // 0 ~ 1 사이의 연속된 값 // sin 함수에 3.1415를 곱하는 이유는 sin 함수의 한 주기가 360도이기 때문임 vec3 color = mix(vec3(0), vec3(1), abs(sin(3.1415 * t))); // or vec3 color = mix(vec3(0), vec3(1), sin(3.1415 * t) * .5 + .5);
원하는 각도를 이루는 선
아래의 이미지는 45도를 이루는 선인데, 이처럼 원하는 각도를 이루는 선을 만들기 위한 코드이다.

uniform vec3 uResolution;
uniform float uTime;
uniform vec4 uMouse;
#define PI (3.141592)
void main() {
vec2 st = gl_FragCoord.xy / uResolution.xy;
st = (gl_FragCoord.xy - .5 * uResolution.xy) / uResolution.y;
float w = fwidth(st.y);
float a = (45.) * PI / 180.0;
float d = dot(st, vec2(cos(a), sin(a)));
d = smoothstep(-w, w, abs(d));
gl_FragColor = vec4(vec3(1. - d), 1.);
}
다각형 그리기
uniform vec3 uResolution;
uniform float uTime;
uniform vec4 uMouse;
#define PI 3.14159265359
#define TWO_PI 6.28318530718
void main(){
vec2 st = gl_FragCoord.xy/uResolution.xy * 2. - 1.; //-1-1
st.x *= uResolution.x/uResolution.y;
vec3 color = vec3(0.0);
float d = 0.0;
// Number of sides of your shape
int N = 6;
// int N = int(floor(mod(uTime * 10., 20.))) + 3;
// Angle and radius from the current pixel
float a = atan(st.x,st.y)+PI;
float r = TWO_PI/float(N);
// Shaping function that modulate the distance
d = cos(floor(.5+a/r)*r-a)*length(st);
// color = vec3(d); // Distance Field
color = vec3(1.0-step(.5, d)); // Fill
// color = vec3(step(.5,d) * step(d,.51)); // Only outline
gl_FragColor = vec4(color,1.0);
}