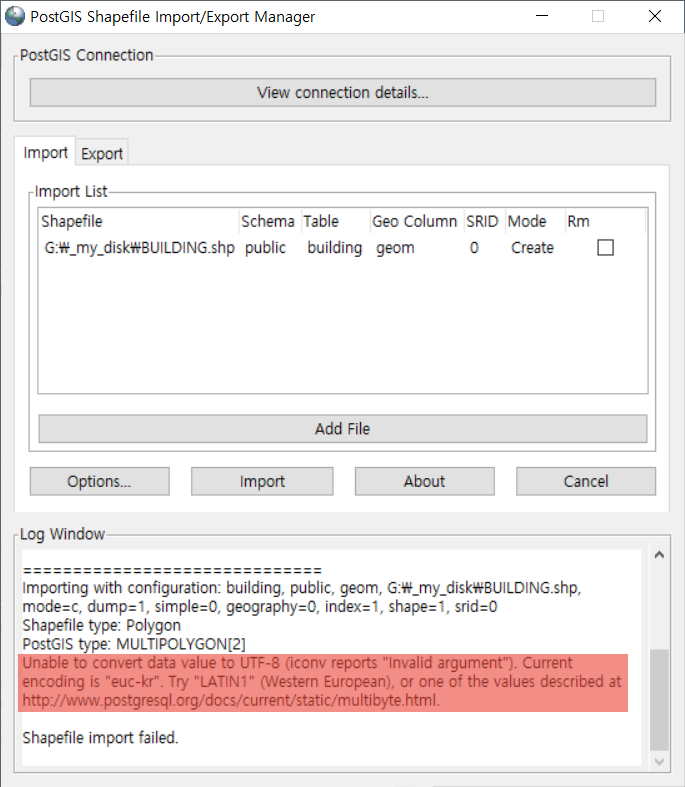
SVG를 이용해 웹에서 원하는 도형을 표현할 수 있는데요. 이 중 어떤 라인의 끝에 도형을 달아 화살표 선을 표현하는 SVG에 대한 코드입니다.
<?xml version="1.0"?>
<svg width="120" height="120" viewBox="0 0 10 10"
xmlns="http://www.w3.org/2000/svg" version="1.1">
<defs>
<marker id="Triangle" viewBox="0 0 10 10" refX="1" refY="5"
markerWidth="6" markerHeight="6" orient="auto">
<path d="M 0 0 L 10 5 L 0 10 z" />
</marker>
</defs>
<polyline points="10,10 100,100" fill="none" stroke="black"
stroke-width="2" marker-end="url(#Triangle)" />
</svg>
코드를 보면 SVG의 기능 중 marker 정의를 이용하고 있습니다. CAD에서의 Block 개념처럼.. 마치 도형을 미리 정의해 두고 재활용하는 방식입니다. marker의 orient를 auto로 지정해 선의 기울기에 맞춰 자동으로 회전할 수 있고, 회전시 원점을 지정하기 위해 refX와 refY값을 이용합니다.
정의해둔 marker는 polyline 등과 같은 SVG 요소의 marker-end 등과 같은 속성에 마커의 ID 값을 지정하면 됩니다.
결과는 아래와 같습니다.
[xyz-ihs snippet=”SVG-MARKER”]
참고로 위의 결과는 IE보다 Chrome이 더 나은 결과를 제공합니다.