작성일자 2011-12-222020-08-03보호된 글: [GIS] BlackPoint, 지도 배경색상 변경 이 콘텐츠는 비밀번호로 보호되어 있습니다. 이 콘텐츠를 보려면 아래에 비밀번호를 입력해주세요. 비밀번호:
작성일자 2011-12-212020-08-03보호된 글: [GIS] BlackPoint, GPS의 좌표계 설정 이 콘텐츠는 비밀번호로 보호되어 있습니다. 이 콘텐츠를 보려면 아래에 비밀번호를 입력해주세요. 비밀번호:
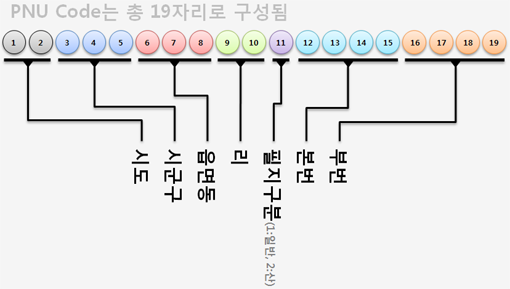
작성일자 2011-12-202017-01-27[GIS] 지적도, 지번(PNU) 코드 구성 실제 PNU 값은 자주 변경되며 행안부의 주민등록주소코드 자료실을 통해 다운로드 받으실 수 있습니다.
작성일자 2011-12-202020-08-03보호된 글: [GIS] BlackPoint, 레이어의 MBR 얻기 이 콘텐츠는 비밀번호로 보호되어 있습니다. 이 콘텐츠를 보려면 아래에 비밀번호를 입력해주세요. 비밀번호:
작성일자 2011-12-172020-08-03보호된 글: [GIS] BlackPoint, 공간연산자 실행 예제 이 콘텐츠는 비밀번호로 보호되어 있습니다. 이 콘텐츠를 보려면 아래에 비밀번호를 입력해주세요. 비밀번호: