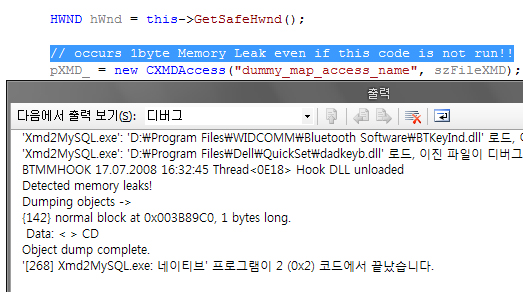
필자가 OpenMP이라는 단어를 처음 들었을때는, 보다 안정적인 멀티 스레드 프로그래밍에 대한 갈증이 한창일 때였습니다. XGE 개발 초기에 데이터 요청과 데이터 가시화를 별도의 스레드로 두고, 다시 데이터 요청을 레이어 단위로 나누어 다시 레이어를 별도의 스레드로 분리시켜야할 필요성에서였는데요. 그러다가 찾은 것이 OpenMP 이였습니다. 처음 접하는 기술인지라… 실제 프로젝트에 적용하지 않고 일단 머리속에 북마크만 해 두었지요.
최근에 다시 모 잡지에서 OpenMP라는 단어를 접하게 되었는데, 요즘 CPU가 죄다 듀얼코어니, 쿼드코어니… 얼마후에는 옥타코어와 같이 하나의 CPU가 2개, 4개, 8개의 CPU의 성능을 낼 수 있는 컴퓨팅 환경이고, 이런 컴퓨팅 리소스를 100% 활용하기 위해 병렬 프로세싱, 다중 스레드, 다중 프로세싱 개발 기법을 속속들이 적용하고 있고, 이 기법이라는게 역사라 불리는 시간에서 지금에 이르기까지 존재하는 스레드를 이용한 방법입니다. 여기에 간단히 스레드를 직접 사용하지 않고 간단/명료한, 하지만 아직은 섬세하지는 않는 멀티 프로세싱 방법인 OpenMP라는 기술이 수년전에 나타났는데, 이 글은 간단한 예로 OpenMP를 접해 보도록 하겠습니다.
먼저 고객으로부터 받은 하나의 요청을 예로 OpenMP의 기능을 느껴보는 것이 가장 좋은 접근법 같습니다. 요청은 테일러급수를 이용해 자연로그에서의 e와 파이(3.1415~)를 구하고 이 둘의 값을 합해 보는 것입니다. 왜 이런것이 필요한지는 생각하지 말고 말입니다. ^^; 이 예는 http://www.kallipolis.com/openmp/1.html 의 OpenMP의 Tutorial에서 가져왔음을 명확히 합니다. 위의 문제를 해결하기 위해서는 먼저 e를 구하고 다음으로 phi를 구한후에 마지막으로 e와 phi를 합하면 끝납니다. 모두 3단계로 나눠지는데, 바로 아래와 같이 말입니다.
- e를 구한다.
- phi를 구한다.
- e와 phi를 합한다.
위의 3 단계를 자세히 살펴보면, 3단계는 1단계와 2단계가 반드시 이뤄져야 하지만, 1단계와 2단계는 완전히 서로 독립적이라는 점입니다. 바로 여기서 1단계와 2단계를 2개의 스레드로 분리해 성능을 높일 수 있다는 것일 알 수 있습니다. 2개의 스레드로 분리하는 방법은 직접 개발자가 스레드 API를 사용해서 분리시킬 수 있는 방법과 OpenMP를 사용해서 그 분리 작업을 맡기는 방법이 있습니다. 여기서는 물론~ OpenMP를 사용해 두개의 스레드로 분리해 보겠습니다.
#include "stdafx.h"
#include
#include
#define num_steps 20000000
int main(int argc, char *argv[])
{
double start, stop;
double e, pi, factorial, product;
int i;
start = clock();
#pragma omp parallel sections num_threads(2)
{
#pragma omp section
{
printf("e started\n"); // 1. 단계: e구하기
e = 1;
factorial = 1;
for (i = 1; i<num_steps; i++) {
factorial *= i;
e += 1.0/factorial;
}
printf("e(%lf) done\n", e);
}
#pragma omp section
{
printf("pi started\n"); // 2. 단계: phi 구하기
pi = 0;
for (i = 0; i < num_steps*10; i++) {
pi += 1.0/(i*4.0 + 1.0);
pi -= 1.0/(i*4.0 + 3.0);
}
pi = pi * 4.0;
printf("pi(%lf) done\n", pi);
}
}
product = e + pi; // 3. 단계: e와 phi 합하기
stop = clock();
printf("Reached result %f in %.3f seconds\n",
product, (stop-start)/1000);
return 0;
}
먼저 살펴 볼 것이 #pragma omp parallel sections num_threads(2)인데, 이 #pragma는 2개의 스레드(num_threads(2))로 실행 구역(section)을 나누겠다는 의미입니다. 그 실행 구역이라는 것이 다름 아닌 e와 phi를 구하는 것인데, 이 실행 구역, 즉 section을 정하는 코드가 바로 다음 코드에 2번 나오는 #pragma section 블럭입니다. 이 블럭은 정확히 e와 phi를 구하는 코드입니다.
여기서 중요한 것은 동기화인데, e와 phi를 계산해서 합하는 것이 최종적인 목표이므로 e의 계산과 phi의 계산이 완전이 완료되어야만 e와 phi를 합할 수가 있다. OpenMP는 #pragma omp parallel sections num_threads를 통해 이 전처리가 규정한 블럭의 코드를 자동으로 동기화 시켜줍니다!! ^^ 와우~
여기서 눈치가 빠른 사람이라면, 위의 코드에서 OpenMP와 관련된 코드를 제거해도 동일한 결과를 낸다는 것입니다. 물론, 싱글 스레드로 돌아가므로 수행 속도는 저하되겠지만 말입니다. 즉, 이를 다시 역으로 생각해보면, 기존에 전혀 멀티 프로세싱을 고려하지 않고 개발된 코드에 대해서 OpenMP를 적절하게 적용하면 큰 코드의 변경 없이도 멀티 프로세싱의 잇점을 추가할 수 있다는 점이겠지요. 필자의 추측으로 OpenMP라는 기술은 아마도… 기존의 싱글 스레드로 작동하는 소프트웨어에 대해서, 멀티코어 CPU의 등장으로 그 하드웨어의 성능을 최대한 끌어내기 위해 등장한 기술로 보입니다.
간단하게 예를 들어 OpenMP를 살펴보았습니다. 이글은 OpenMP의 많은 기능 중에 매우 간단하고 기본적인 예를 든 것입니다. 추후 기회가 된다면 더 많은 OpenMP의 정보를 제공할 수 있도록 하겠습니다. 그때까지 참지 못하겠다면, http://www.kallipolis.com/openmp/index.html 를 참고하길 바랍니다.