C++을 학습하던 때에 제법 깊이 있게 생각하며 봤던 C++ 내용 중 복사생성자와 소멸자 그리고 대입연산자가 있었습니다. 마치 스타크래프트에서 등장하는 유닛들의 이름을 한글화 해 놓은 것은 이 3가지에 대해서 정리해 봅니다.
기본적으로 C++은 복사생성자, 소멸자, 대입연산자를 프로그래머가 정의해 놓지 않을 경우 정해진 기본 기능을 수행하는 복사생성자와 소멸자, 대입연산자를 만들어 놓는다고 가정할 수 있습니다.
기본 기능에 대한 복사생성자는 해당 클래스의 맴버 변수의 값을 그대로 복사합니다. 또한 기본 기능에 대한 소멸자는 해당 클래스의 맴버 변수의 소멸자를 호출해 줍니다. 그리고 기본기능에 대한 대입연산자는 해당 클래스의 맴버 변수의 값을 그대로 복사합니다.
여기서 언급된 맴버 변수의 값에 대한 복사라함은 단순한 값의 복사로써 만약 맴버 변수가 포인터일 경우 그 변수가 가르키고 있는 값까지 복사하는것이 아닌 주소값만을 복사한다는 의미입니다. 바로 이 포인트에 대한 부분이 C++에서 복사생성자와 소멸자, 대입연산자의 중요함이 강조되는 부분입니다.
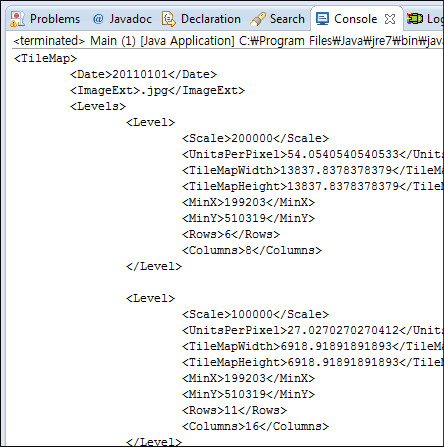
아래의 코드는 이들 세가지(복사생성자, 소멸자, 대입연산자)에 대한 작성방법 및 이들을 제공하지 않았을 경우 어떻게 이들 세가지가 호출되는지를 보여주는 예입니다. 작성방법은 클래스 M에서 파악할 수 있고 호출 순서와 여부는 클래스 X에서 파악할 수 있습니다. 클래스 X는 이들 셋을 정의하고 있지 않으므로 C++에서 기본적으로 제공하는 기능에 대해 수행된다고 확신할 수 있습니다.
먼저 클래스 M에 대한 코드입니다.
class M {
public:
M() {
cout << "M::default-ctr is called" << endl;
}
M(const M&) {
cout << "M::copy-ctr is called" << endl;
}
~M() {
cout << "M::dtr is called" << endl;
}
M& operator=(const M&) {
cout << "M::oper= is called" << endl;
return *this;
}
};
여기서 기본생성자(M::default-ctr is called를 출력하는 함수)가 추가로 제공되고 있습니다. C++은 프로그래머가 생성자를 추가하지 않으면 기본생성자를 자동으로 추가해 주지만, 여기서는 복사생성자를 추가하고 있음으로 프로그래머가 직접 기본 생성자를 추가해 주어야 합니다.
다음은 클래스 X이며 이 클래스는 복사생성자와 소멸자, 대입연산자를 프로그래머가 제공하지 않으며 단순히 맴버 변수로써 클래스 M만을 가지고 있습니다.
class X {
M m;
};
이제 클래스 X를 생성하고 대입하는 코드를 통해 복사생성자와 소멸자, 대입연산자의 호출을 확인해 보도록 하겠습니다.
X x;
X y = x;
x = y;
실행 결과는 다음과 같습니다.
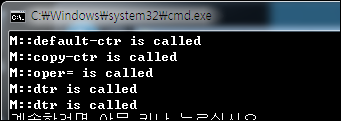
1번 코드에 의해서 M::default-ctr is called가 표시되며 2번 코드에 의해서 M::copy-ctr is called가 호출됩니다. 그리고 3번 코드에 의해서 M::oper= is called가 호출됩니다. 그리고 이 프로그램의 유효범위가 종료됨으로써 직역변수로 선언된 x와 y에 대한 소멸자가 각각 1번씩 호출됩니다.