딥러닝 신경망을 이용하여 항공영상의 해상도를 강화하는 GeoAI의 기술중 하나를 소개합니다. 흔히 슈퍼 레졸루션(Super Resolution)이라 불리며, 25cm 급 해상도의 항공영상을 통해 학습 DB를 구축하여 Super Resoultion에 대한 신경망을 학습한 후 그 결과를 정리하였습니다.
저해상도 영상을 고해상도 영상으로 만들기 위한, 신경망을 활용하기 이전의 방법은 인접 픽셀간의 보간을 통한 Bicubic Interpolation 방식, 이미지 데이터베이스에서 유사한 장면의 이미지를 선택해 그 이미지를 결과로 하는 Best Scene Match 방식, 좀더 큰 유사한 패턴을 가져와 작은 패턴 위치에 붙여 넣는 Self-Similarity 기반 방식 등이 있었고, 그 후 신경망을 활용하여 더욱 성능이 향상된, 또한 보다 범용적으로 활용할 수 있게 되었습니다.

위의 그림(출처: EXTREMETECH)은 Orignal 영상을 2배 확대했을 때, 가장 가까운 픽셀을 활용한 보간법을 통한 방법인 Nearest Neighbor 방식과 Super Resolution 방식의 결과 비교입니다. 바로 이러한 Super Resolution을 저해상도의 항공영상에 적용하여 더 높은 해상도를 가지는 영상을 생성하는데 활용할 수 있습니다.
딥러닝 신경망을 활용한 해상도 강화는 Convolutional Layer를 사용하는 CNN을 이용한 모델로 시작하여, Skip-Connection 기법(잔차 연결;Residual-Connection 또는 숏컷;Short-Cut이라고도 함)을 적용한 VDSR 모델로 발전하였고, 다음에는 적대적 생성 신경망인 GAN을 활용한 SRGAN 모델이 연구 되었습니다. VDSR 모델은 기본적으로 CNN의 사용에 Skip-Connection 기법을 추가한 것이고, SRGAN 모델은 CNN 및 VDSR에서 의미 있게 사용한 Skip-Connection 기법을 Generator에 적용한 GAN 방식으로, 이전의 기반 기술을 새로운 기술에서 보다 효과적으로 활용하고 있음을 알 수 있습니다.
Super Resolution은 저해상도의 이미지를 고해상도의 이미지로 만들어 주는 기술입니다. 이를 위한 신경망 학습에는 저해상도의 이미지와 해당 저해상도 이미지에 대한 고해상도 이미지가 필요 합니다. 이를 위해 먼저 많은 고해상도 이미지를 작은 크기로 줄여 저해상도 이미지로 만들 수 있고, 이렇게 만든 저해상도 이미지를 입력 데이터로, 원래의 고해상도 데이터를 정답인 레이블 데이터로 사용하게 됩니다. 즉, 레이블 데이터는 사람이 별도로 구축하지 않고, 학습시 자동으로 생성해 낼 수 있어 더욱 활용도가 매우 높은 기술입니다.
이 글은 적대적 생성 신경망인 GAN을 이용하여 항공영상의 해상도를 향상시키는 신경망에 대한 구현 사례에 대한 결과를 소개하는데 초점을 맞췄으며, GAN에 대한 보다 상세한 기술적 내용과 구현은 다음 글을 참고하기 바랍니다.
GAN은 기본적으로 생성자(Generator)와 판별자(Discriminator)에 대한 모델 2개가 필요하며, 본 사례에서 사용한 사용한 신경망 모델은 다음과 같습니다.
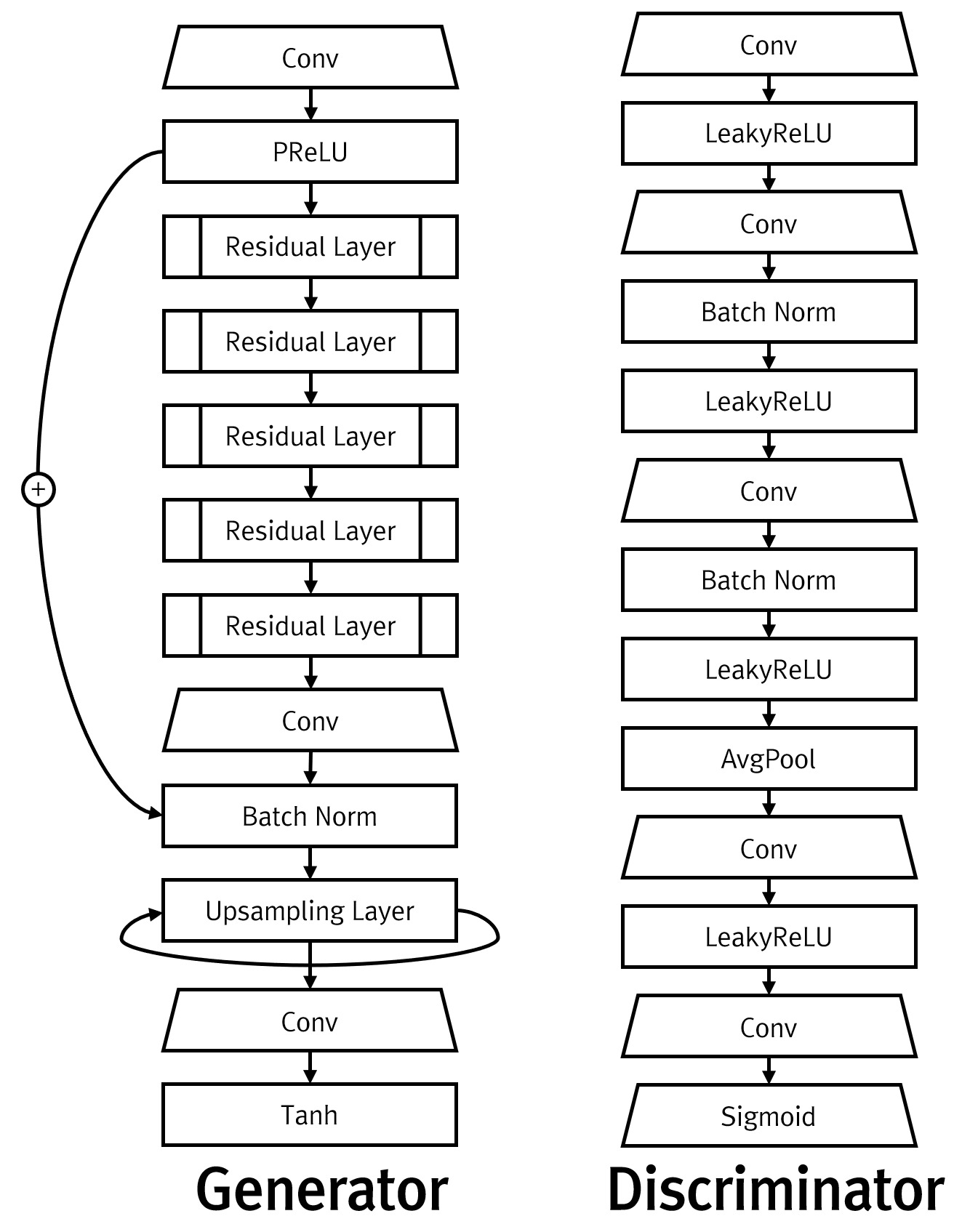
위의 Generator와 Discriminator 신경망 모델의 학습에는 25cm급 항공영상을 1/8 크기로 줄여 해상도를 대폭 낮췄습니다. 즉, 25cm 급을 200cm 급으로 낮춘 것으로 샘플 중 3가지만 언급하면 다음과 같습니다.

원본 이미지에 비해 그 품질이 현격히 낮아진 것을 확인할 수 있습니다. 이처럼 낮아진 저해상도 영상을 상대적으로 더 향상시키고자 먼저 보유하고 있는 항공영상을 768×768 픽셀 크기로 잘라내어, 총 3766개의 학습 영상을 구축했습니다. 이 학습 데이터를 활용하여 총 50 번의 신경망 학습을 수행했을 때, 결과는 다음과 같았습니다. 아래의 결과는 신경망이 학습시에 한번도 보지 못한 영상에 대한 결과입니다. 각 줄의 첫번째가 입력값인 저해상도 영상이고 세번째가 저해상도 영상을 Super Resolution으로 향상시킨 결과입니다. 가운데 이미지는 저해상도 이미지를 생성해 내기 위한 원본 이미지로써 신경망 학습 시 정답으로 사용되는 레이블 데이터입니다.







위의 결과는 GAN 방식을 이용한 Super Resolution입니다. 이외에 기본적인 CNN만을 사용한 모델과 학습을 좀더 잘되게 하기 위해 Skip-Connection 기법을 적용한 VDSR 등이 있다고 앞서 언급했습니다. 이 셋 모두 저해상도 이미지를 고해상도 이미지로 변환하기 위해 이미지의 크기를 확대하기 위한 방법으로 Transposed Convolutional 방식과 Sub-Pixel 방식이 있어, 대상이 되는 이미지의 성격에 따라 어떤 모델을, 세부적으로는 모델을 구성하는 레이어를 어떻게 구성할지를 결정해야 합니다. 또한 최적의 하이퍼파라메터도 반복적인 학습 및 검증을 통해 다양하게 조정해야 합니다.
또한 구슬이 서말이라도 꿰어야 보배라고 하듯이 Super Resolution을 이용한 항공영상이나 위성영상의 해상도를 보강하는 기술이 실제 상황에 사용하기 위해서는 단순이 딥러닝의 신경망 학습과 의미있는 결과 도출만으로는 충분하지 않습니다. 이러한 신경망의 의미있는 결과를 실제 대용량의 영상에 적용하고 실제 사용자가 사용할 수 있는 효과적 UI과 성능을 갖춘 어플리케이션으로 개발되어야 할 것입니다.
![$$loss(x,class)=-\log\biggl(\frac{\exp(x[class])}{\sum_{j}{\exp(x[j])}}\biggr)=-x[class]+\log\biggl(\sum_{j}{\exp(x[j])}}\biggr)$$](http://www.gisdeveloper.co.kr/wp-content/ql-cache/quicklatex.com-f3208d5dfaaecd0f28069ec368ceb1f7_l3.png "Rendered by QuickLaTeX.com")