원하는 폴더 안에.. 특정한 확장자를 가지는 파일 목록을 얻어야 할때가 있습니다. 예를 들어서 D:/TEMP라는 폴더안에 확장자가 SHP인 파일의 목록을 배열 형태로 반환하도록 하는 경우이지요. 이때 사용할만한 함수입니다.
private Vector getFileNames(String targetDirName, String fileExt) {
Vector fileNames = new Vector();
File dir = new File(targetDirName);
fileExt = fileExt.toLowerCase();
if(dir.isDirectory()) {
String dirName = dir.getPath();
String[] filenames = dir.list(null);
int cntFiles = filenames.length;
for(int iFile=0; iFile String filename = filenames[iFile];
String fullFileName = dirName + "/" + filename;
File file = new File(fullFileName);
boolean isDirectory = file.isDirectory();
if(!isDirectory && filename.toLowerCase().endsWith(fileExt)) {
fileNames.add(fullFileName);
}
}
}
return fileNames;
}
제가 이 함수가 필요했던 이유는.. 특정 폴더에 존재하는 수백개의 항공영상이나 수백개의 SHP 파일을 한꺼번에 레이어로 추가하고자 하는 필요 때문이였습니다.
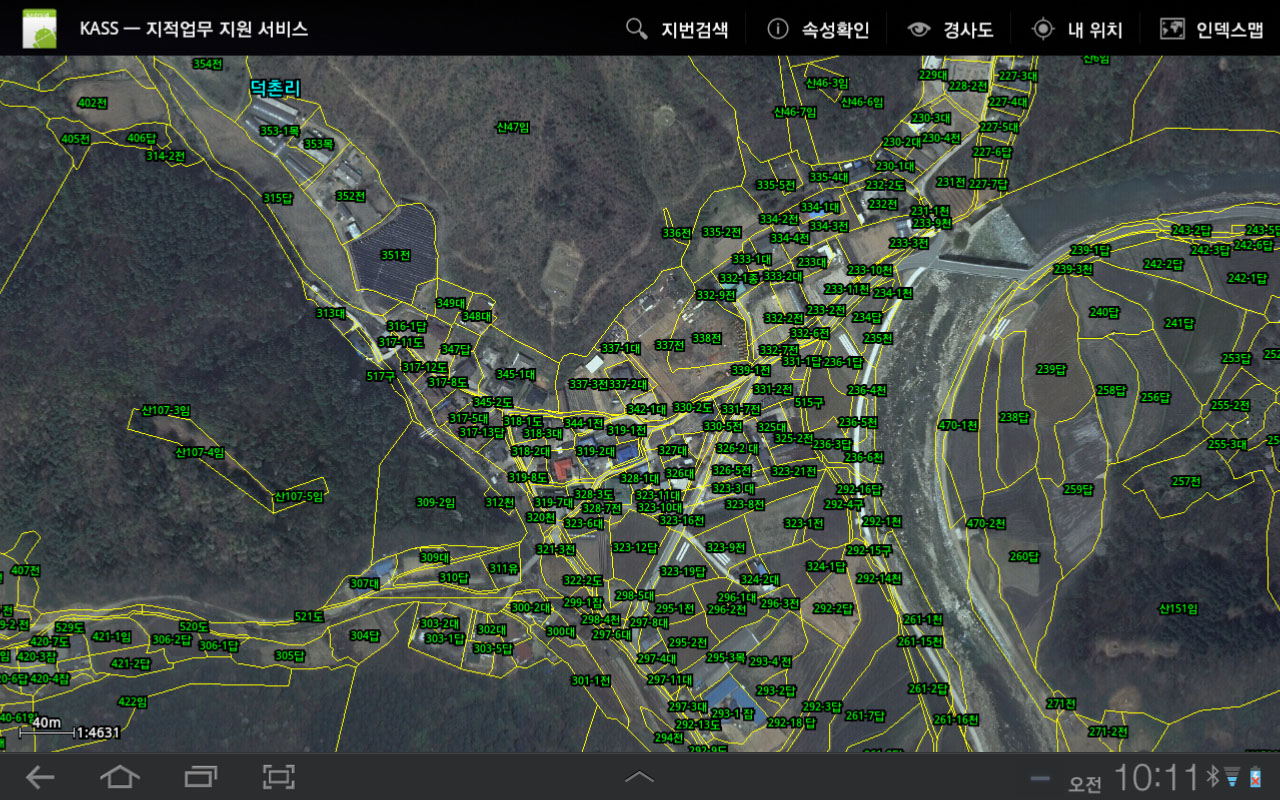
아래의 코드는 안드로이드 기반의 GIS 엔진인 블랙포인트에서 위의 함수를 사용해 25cm 해상도의 192개의 항공영상(GEOTIFF 기준으로 40GB 이상)과 일정한 격자로 나눈 SHP 파일 185개(전체 용량 85MB)를 올리는 코드예입니다.
LayerManager layerMan = map.getLayerManager();
String ess = Environment.getExternalStorageState();
String sdCardPath = null;
if(ess.equals(Environment.MEDIA_MOUNTED)) {
sdCardPath = Environment.getExternalStorageDirectory().getAbsolutePath();
String rootDir = sdCardPath + "/mapdata/yp";
// 항공사진 레이어 추가
Vector xrrFiles = getFileNames(rootDir +"/XrR", "xrr");
for(int i=0; i ILayer layer = new TileImageLayer("xrr_" + i, xrrFiles.get(i), false);
layerMan.addLayer(layer);
}
// 수치지도 레이어 추가
Vector cassFiles = getFileNames(rootDir + "/CBND", "shp");
int cntCbndLyr = cassFiles.size();
for(int i=0; i ILayer layer = new ShapeLayer("cbnd_" + i, cassFiles.get(i));
layerMan.addLayer(layer);
ShapeLayerLabel roadLbl = (ShapeLayerLabel)shpLyr.getLabel();
roadLbl.setFieldName("JIBUN");
roadLbl.setEnable(true);
roadLbl.getFontSymbol().setTextSize(11);
SimpleDrawShapeTheme roadTheme = (SimpleDrawShapeTheme)shpLyr.getTheme();
roadTheme.getFillSymbol().setHollow(true);
roadLbl.getFontSymbol().setTextColor(Color.GREEN);
roadTheme.getStrokeSymbol().setColor(Color.YELLOW);
}
아래는 위의 코드에 반영된 시스템에 대한 실행 화면입니다. 클릭하면 원본 크기로 볼 수 있습니다.